\n
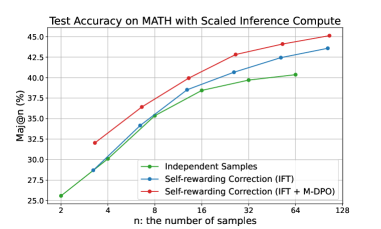
## Line Chart: Test Accuracy on MATH with Scaled Inference Compute
### Overview
The image presents a line chart illustrating the relationship between the number of samples ('n') and the Major@n accuracy (%) for three different methods: Independent Samples, Self-rewarding Correction (IFT), and Self-rewarding Correction (IFT + M-DPO). The chart demonstrates how accuracy improves as the number of samples increases, with varying performance levels across the three methods.
### Components/Axes
* **Title:** "Test Accuracy on MATH with Scaled Inference Compute" (positioned at the top-center)
* **X-axis:** "n: the number of samples" (positioned at the bottom-center). The axis is scaled logarithmically with markers at 2, 4, 8, 16, 32, 64, and 128.
* **Y-axis:** "Maj@n (%)" (positioned at the left-center). The axis ranges from approximately 25% to 45%.
* **Legend:** Located at the top-right corner.
* Independent Samples (Green Line with Green Circle Markers)
* Self-rewarding Correction (IFT) (Blue Line with Blue Circle Markers)
* Self-rewarding Correction (IFT + M-DPO) (Red Line with Red Circle Markers)
* **Gridlines:** Horizontal and vertical gridlines are present to aid in reading values.
### Detailed Analysis
**Independent Samples (Green Line):**
The green line shows an upward trend, indicating increasing accuracy with more samples.
* n = 2: Maj@n ≈ 26%
* n = 4: Maj@n ≈ 30%
* n = 8: Maj@n ≈ 34%
* n = 16: Maj@n ≈ 38%
* n = 32: Maj@n ≈ 39.5%
* n = 64: Maj@n ≈ 40.5%
* n = 128: Maj@n ≈ 41%
**Self-rewarding Correction (IFT) (Blue Line):**
The blue line also exhibits an upward trend, but starts at a higher accuracy than the Independent Samples and shows a steeper increase initially.
* n = 2: Maj@n ≈ 32%
* n = 4: Maj@n ≈ 35%
* n = 8: Maj@n ≈ 38%
* n = 16: Maj@n ≈ 40%
* n = 32: Maj@n ≈ 42%
* n = 64: Maj@n ≈ 43%
* n = 128: Maj@n ≈ 43.5%
**Self-rewarding Correction (IFT + M-DPO) (Red Line):**
The red line demonstrates the highest accuracy across all sample sizes and has the steepest upward slope.
* n = 2: Maj@n ≈ 32%
* n = 4: Maj@n ≈ 35%
* n = 8: Maj@n ≈ 37%
* n = 16: Maj@n ≈ 40%
* n = 32: Maj@n ≈ 42.5%
* n = 64: Maj@n ≈ 44%
* n = 128: Maj@n ≈ 45%
### Key Observations
* The "Self-rewarding Correction (IFT + M-DPO)" method consistently outperforms both "Independent Samples" and "Self-rewarding Correction (IFT)" across all sample sizes.
* The performance gap between the methods widens as the number of samples increases.
* All three methods show diminishing returns in accuracy as the number of samples grows beyond 64.
* The "Independent Samples" method has the lowest accuracy overall.
### Interpretation
The data suggests that incorporating M-DPO into the Self-rewarding Correction (IFT) method significantly improves test accuracy on the MATH dataset, especially as the number of samples increases. This indicates that the M-DPO component provides a valuable enhancement to the learning process. The logarithmic scale of the x-axis suggests that the initial gains in accuracy are more substantial with smaller sample sizes. The diminishing returns observed at higher sample sizes may indicate a point of saturation where adding more data does not yield significant improvements in accuracy. The consistent outperformance of the combined method highlights the synergistic effect of IFT and M-DPO. This chart provides evidence for the effectiveness of self-rewarding correction techniques, particularly when combined with M-DPO, for improving performance on mathematical reasoning tasks.