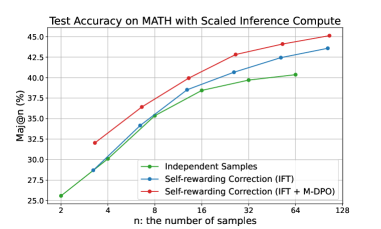
## Line Graph: Test Accuracy on MATH with Scaled Inference Compute
### Overview
The graph illustrates the relationship between test accuracy (Maj@n, in %) and the number of samples (n) for three distinct methods: Independent Samples, Self-rewarding Correction (IFT), and Self-rewarding Correction (IFT + M-DPO). All three methods show an upward trend in accuracy as the number of samples increases, with the IFT + M-DPO method consistently outperforming the others.
### Components/Axes
- **Title**: "Test Accuracy on MATH with Scaled Inference Compute"
- **Y-axis**: "Maj@n (%)" (ranging from 25% to 45%)
- **X-axis**: "n: the number of samples" (ranging from 2 to 128)
- **Legend**: Located at the bottom-right corner, with three entries:
- Green: Independent Samples
- Blue: Self-rewarding Correction (IFT)
- Red: Self-rewarding Correction (IFT + M-DPO)
### Detailed Analysis
- **Independent Samples (Green Line)**:
- Starts at ~25% accuracy at n=2.
- Increases steadily, reaching ~30% at n=4, ~35% at n=8, ~37.5% at n=16, ~39.5% at n=32, ~40% at n=64, and ~40.5% at n=128.
- **Self-rewarding Correction (IFT) (Blue Line)**:
- Starts at ~27.5% accuracy at n=2.
- Rises to ~30% at n=4, ~35% at n=8, ~38% at n=16, ~41% at n=32, ~43% at n=64, and ~44% at n=128.
- **Self-rewarding Correction (IFT + M-DPO) (Red Line)**:
- Starts at ~32% accuracy at n=2.
- Increases to ~35% at n=4, ~38% at n=8, ~40% at n=16, ~42.5% at n=32, ~44% at n=64, and ~45% at n=128.
### Key Observations
1. **Upward Trends**: All three methods show consistent improvement in accuracy as the number of samples increases.
2. **Performance Hierarchy**: The red line (IFT + M-DPO) consistently outperforms the blue (IFT) and green (Independent Samples) lines across all sample sizes.
3. **Divergence at Larger Samples**: The gap between the red and blue lines narrows slightly at n=128, but the red line remains the highest.
4. **Slowest Growth**: The green line (Independent Samples) exhibits the least improvement, with minimal gains beyond n=32.
### Interpretation
The data demonstrates that combining Self-rewarding Correction (IFT) with M-DPO significantly enhances test accuracy compared to using IFT alone or independent samples. The M-DPO component appears to amplify the benefits of scaled inference compute, particularly at larger sample sizes. This suggests that M-DPO may improve the efficiency or effectiveness of the inference process, leading to better generalization. The Independent Samples method, while showing improvement, lags behind the other two, highlighting the value of structured correction mechanisms in the MATH dataset context.