TECHNICAL ASSET FINGERPRINT
81be01878541d9eb93406229
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
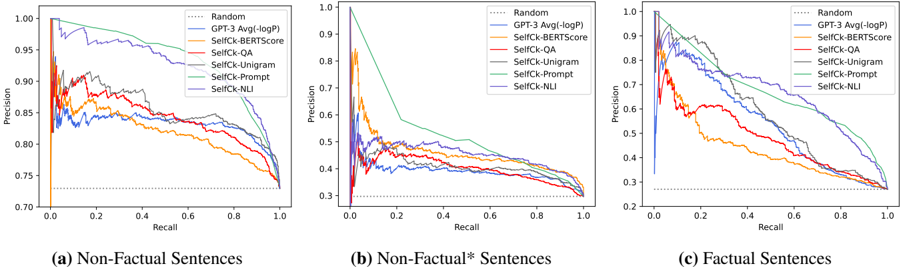
## Chart Type: Precision-Recall Curves
### Overview
The image presents three precision-recall curves, comparing different methods for evaluating the factuality of sentences. The three plots represent different categories of sentences: (a) Non-Factual Sentences, (b) Non-Factual* Sentences, and (c) Factual Sentences. Each plot shows the precision (y-axis) versus recall (x-axis) for several methods, including a random baseline, GPT-3, and several "SelfCk" methods.
### Components/Axes
* **X-axis (Recall):** Ranges from 0.0 to 1.0 in increments of 0.2.
* **Y-axis (Precision):**
* Plot (a): Ranges from 0.70 to 1.00 in increments of 0.05.
* Plot (b): Ranges from 0.2 to 1.0 in irregular increments.
* Plot (c): Ranges from 0.2 to 1.0 in irregular increments.
* **Legend (Top-Right of each plot):**
* `Random`: Dotted black line.
* `GPT-3 Avg(-logP)`: Solid blue line.
* `SelfCk-BERTScore`: Solid orange line.
* `SelfCk-QA`: Solid red line.
* `SelfCk-Unigram`: Solid gray line.
* `SelfCk-Prompt`: Solid light green line.
* `SelfCk-NLI`: Solid purple line.
* **Titles:**
* (a) Non-Factual Sentences
* (b) Non-Factual* Sentences
* (c) Factual Sentences
### Detailed Analysis
#### (a) Non-Factual Sentences
* **Random (Dotted Black):** Flat line at approximately 0.73 precision.
* **GPT-3 Avg(-logP) (Solid Blue):** Starts at approximately 1.0 precision at 0.0 recall, decreases to approximately 0.82 precision at 1.0 recall.
* **SelfCk-BERTScore (Solid Orange):** Starts at approximately 0.82 precision at 0.0 recall, decreases to approximately 0.75 precision at 1.0 recall.
* **SelfCk-QA (Solid Red):** Starts at approximately 0.90 precision at 0.0 recall, decreases to approximately 0.78 precision at 1.0 recall.
* **SelfCk-Unigram (Solid Gray):** Starts at approximately 0.90 precision at 0.0 recall, decreases to approximately 0.78 precision at 1.0 recall.
* **SelfCk-Prompt (Solid Light Green):** Starts at approximately 1.0 precision at 0.0 recall, decreases to approximately 0.93 precision at 1.0 recall.
* **SelfCk-NLI (Solid Purple):** Starts at approximately 0.89 precision at 0.0 recall, decreases to approximately 0.80 precision at 1.0 recall.
#### (b) Non-Factual* Sentences
* **Random (Dotted Black):** Flat line at approximately 0.28 precision.
* **GPT-3 Avg(-logP) (Solid Blue):** Starts at approximately 0.5 precision at 0.0 recall, decreases to approximately 0.38 precision at 1.0 recall.
* **SelfCk-BERTScore (Solid Orange):** Starts at approximately 0.85 precision at 0.0 recall, decreases sharply, then fluctuates around 0.4 precision at 1.0 recall.
* **SelfCk-QA (Solid Red):** Starts at approximately 0.45 precision at 0.0 recall, decreases to approximately 0.38 precision at 1.0 recall.
* **SelfCk-Unigram (Solid Gray):** Starts at approximately 0.98 precision at 0.0 recall, decreases sharply to approximately 0.55 precision at 0.4 recall, then decreases slowly to approximately 0.4 precision at 1.0 recall.
* **SelfCk-Prompt (Solid Light Green):** Starts at approximately 1.0 precision at 0.0 recall, decreases sharply to approximately 0.55 precision at 0.4 recall, then decreases slowly to approximately 0.45 precision at 1.0 recall.
* **SelfCk-NLI (Solid Purple):** Starts at approximately 0.55 precision at 0.0 recall, decreases to approximately 0.38 precision at 1.0 recall.
#### (c) Factual Sentences
* **Random (Dotted Black):** Flat line at approximately 0.28 precision.
* **GPT-3 Avg(-logP) (Solid Blue):** Starts at approximately 0.95 precision at 0.0 recall, decreases to approximately 0.35 precision at 1.0 recall.
* **SelfCk-BERTScore (Solid Orange):** Starts at approximately 0.90 precision at 0.0 recall, decreases sharply, then fluctuates around 0.35 precision at 1.0 recall.
* **SelfCk-QA (Solid Red):** Starts at approximately 0.75 precision at 0.0 recall, decreases to approximately 0.35 precision at 1.0 recall.
* **SelfCk-Unigram (Solid Gray):** Starts at approximately 1.0 precision at 0.0 recall, decreases sharply to approximately 0.55 precision at 0.4 recall, then decreases slowly to approximately 0.35 precision at 1.0 recall.
* **SelfCk-Prompt (Solid Light Green):** Starts at approximately 1.0 precision at 0.0 recall, decreases sharply to approximately 0.55 precision at 0.4 recall, then decreases slowly to approximately 0.45 precision at 1.0 recall.
* **SelfCk-NLI (Solid Purple):** Starts at approximately 0.95 precision at 0.0 recall, decreases to approximately 0.35 precision at 1.0 recall.
### Key Observations
* **Non-Factual Sentences:** All methods perform significantly better than random. SelfCk-Prompt consistently maintains the highest precision across all recall values.
* **Non-Factual\* Sentences:** SelfCk-Prompt and SelfCk-Unigram start with high precision but drop sharply as recall increases. GPT-3 and SelfCk-NLI show more stable performance.
* **Factual Sentences:** Similar to Non-Factual\* Sentences, SelfCk-Prompt and SelfCk-Unigram start high but drop sharply. All methods converge to a similar precision level at high recall.
* The "Random" baseline provides a consistent lower bound for performance across all three sentence types.
### Interpretation
The precision-recall curves illustrate the trade-off between precision and recall for different methods of evaluating sentence factuality. The performance varies significantly depending on the type of sentence (Non-Factual, Non-Factual*, Factual).
* For Non-Factual sentences, the SelfCk-Prompt method appears to be the most effective, maintaining high precision even at high recall. This suggests it is good at identifying non-factual sentences without sacrificing the ability to find most of them.
* For Non-Factual\* and Factual sentences, the SelfCk-Prompt and SelfCk-Unigram methods initially perform well but suffer a significant drop in precision as recall increases. This indicates that while they are good at identifying some factual/non-factual\* sentences, they also produce many false positives as they try to identify more.
* The GPT-3 Avg(-logP) and SelfCk-NLI methods show more consistent performance across all sentence types, suggesting a more balanced approach to factuality assessment.
* The "Non-Factual\*" category seems to present a more challenging evaluation scenario, as all methods show lower precision compared to the "Non-Factual" category. This could be due to the nature of the sentences in this category, which might be more ambiguous or difficult to classify.
DECODING INTELLIGENCE...