## Diagram: XAI Methods in LMs
### Overview
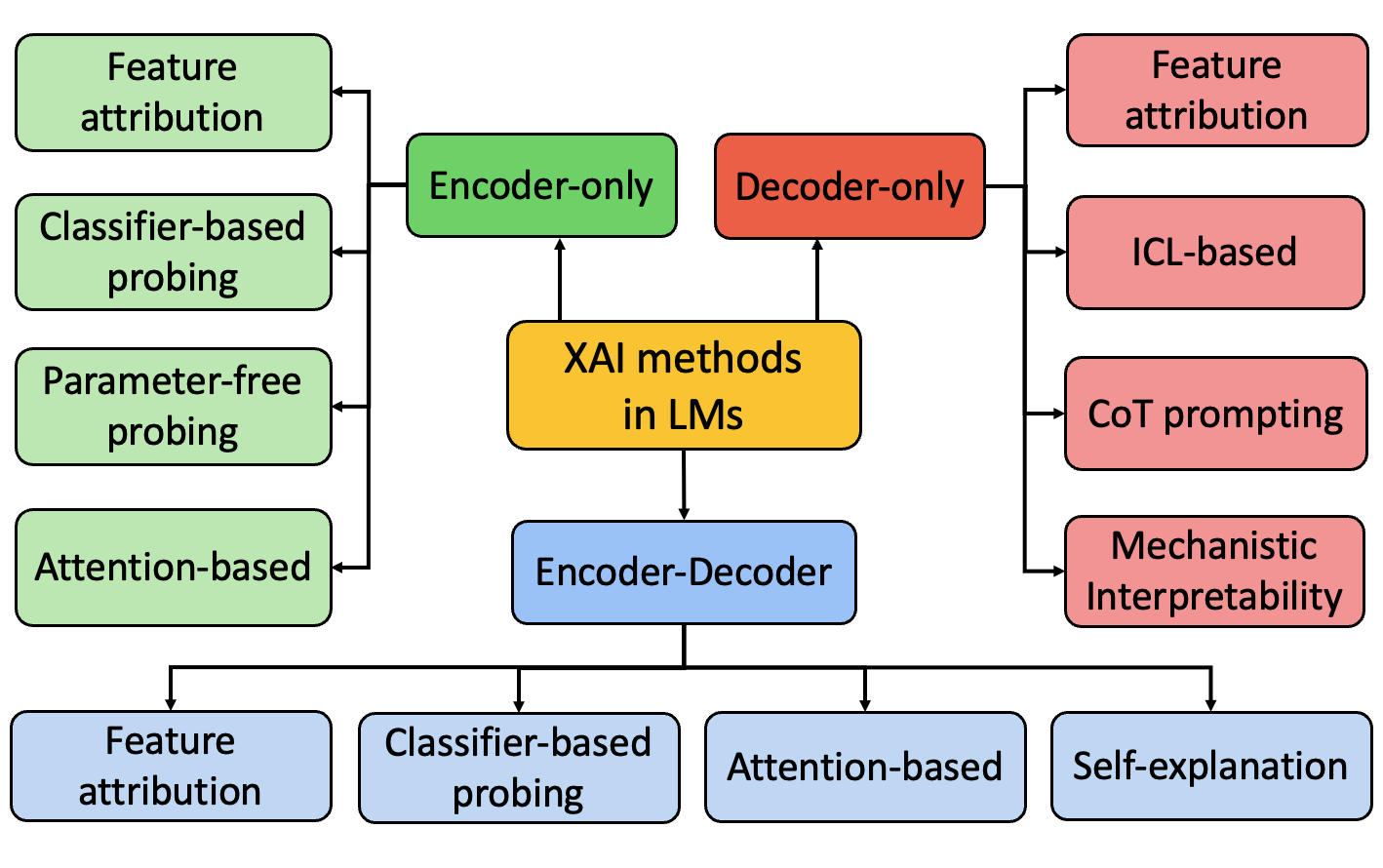
The image is a flowchart illustrating the categorization of Explainable AI (XAI) methods in Language Models (LMs). The diagram branches out from a central node ("XAI methods in LMs") to different model architectures (Encoder-only, Decoder-only, Encoder-Decoder) and then further categorizes XAI techniques based on these architectures.
### Components/Axes
* **Central Node:** "XAI methods in LMs" (yellow box)
* **Model Architectures:**
* "Encoder-only" (green box)
* "Decoder-only" (red box)
* "Encoder-Decoder" (blue box)
* **XAI Techniques (Encoder-only):** (green boxes)
* "Feature attribution"
* "Classifier-based probing"
* "Parameter-free probing"
* "Attention-based"
* **XAI Techniques (Decoder-only):** (red boxes)
* "Feature attribution"
* "ICL-based"
* "CoT prompting"
* "Mechanistic Interpretability"
* **XAI Techniques (Encoder-Decoder):** (blue boxes)
* "Feature attribution"
* "Classifier-based probing"
* "Attention-based"
* "Self-explanation"
### Detailed Analysis
The diagram shows a hierarchical structure. The central node "XAI methods in LMs" branches into three main categories based on model architecture: Encoder-only, Decoder-only, and Encoder-Decoder. Each of these categories then branches out into specific XAI techniques.
* **XAI methods in LMs:** Located in the center of the diagram, represented by a yellow box.
* **Encoder-only:** Located above and to the left of the central node, represented by a green box.
* **Feature attribution:** Located to the left of the "Encoder-only" node, represented by a green box.
* **Classifier-based probing:** Located below "Feature attribution", represented by a green box.
* **Parameter-free probing:** Located below "Classifier-based probing", represented by a green box.
* **Attention-based:** Located below "Parameter-free probing", represented by a green box.
* **Decoder-only:** Located above and to the right of the central node, represented by a red box.
* **Feature attribution:** Located to the right of the "Decoder-only" node, represented by a red box.
* **ICL-based:** Located below "Feature attribution", represented by a red box.
* **CoT prompting:** Located below "ICL-based", represented by a red box.
* **Mechanistic Interpretability:** Located below "CoT prompting", represented by a red box.
* **Encoder-Decoder:** Located below the central node, represented by a blue box.
* **Feature attribution:** Located below the "Encoder-Decoder" node, represented by a blue box.
* **Classifier-based probing:** Located to the right of "Feature attribution", represented by a blue box.
* **Attention-based:** Located to the right of "Classifier-based probing", represented by a blue box.
* **Self-explanation:** Located to the right of "Attention-based", represented by a blue box.
### Key Observations
* "Feature attribution" appears as an XAI technique for all three model architectures (Encoder-only, Decoder-only, and Encoder-Decoder).
* Some techniques are specific to certain architectures (e.g., "ICL-based" and "CoT prompting" are only listed under "Decoder-only").
* The diagram provides a high-level overview and does not delve into the specifics of each XAI technique.
### Interpretation
The diagram provides a structured overview of how XAI methods are categorized based on the underlying architecture of the language model. It highlights that certain XAI techniques are more applicable or relevant to specific model architectures. The presence of "Feature attribution" across all architectures suggests its broad applicability. The diagram serves as a useful tool for understanding the landscape of XAI methods in LMs and their relationship to different model types. It suggests that the choice of XAI method may depend on the specific architecture of the language model being used.