\n
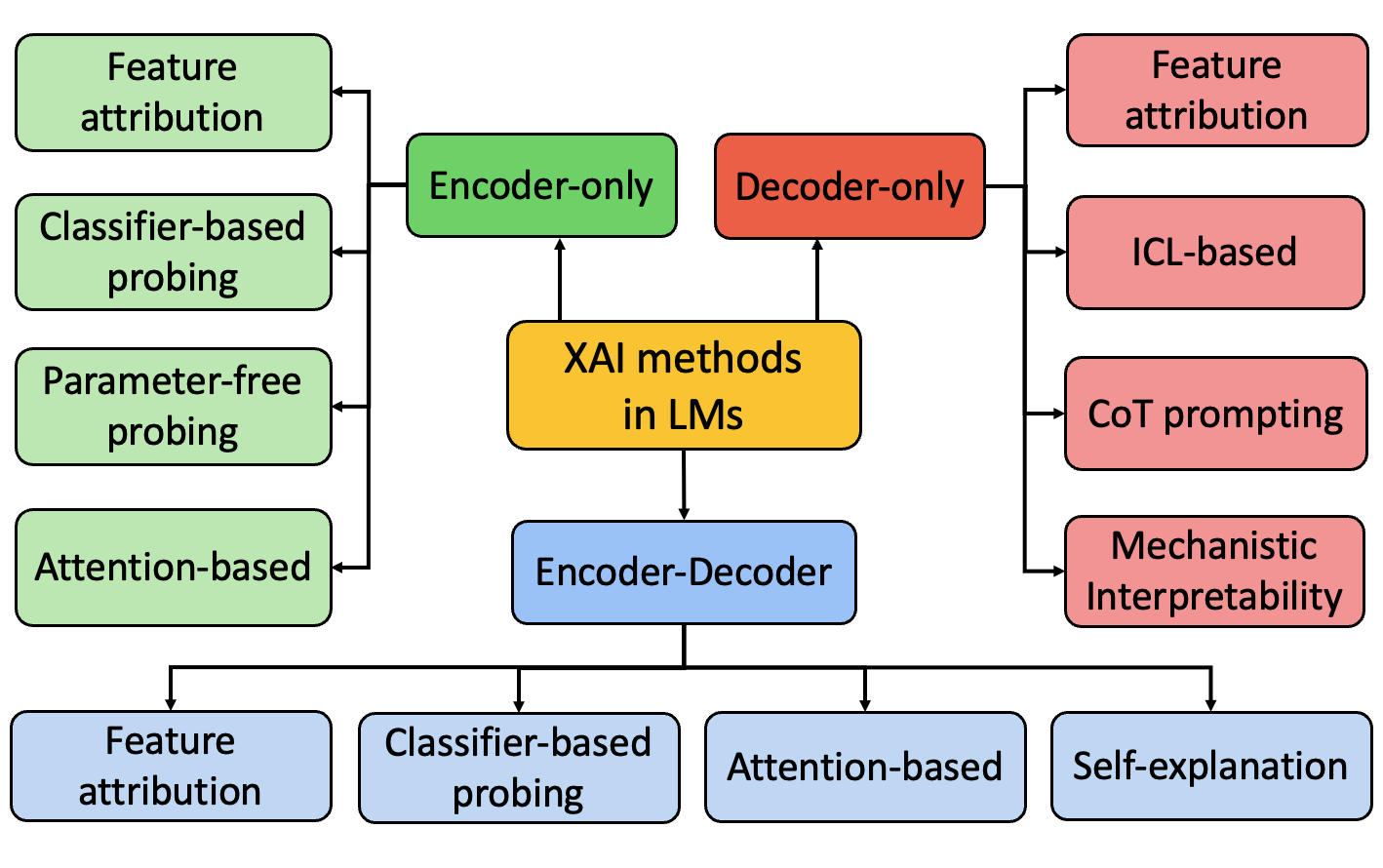
## Diagram: XAI Methods in LMs
### Overview
This diagram illustrates the relationship between different Explainable AI (XAI) methods applied to Large Language Models (LMs). It depicts a central node labeled "XAI methods in LMs" with various methods branching out from it, categorized by model architecture (Encoder-only, Decoder-only, Encoder-Decoder). The diagram shows how these methods can be further categorized into specific techniques.
### Components/Axes
The diagram consists of interconnected rectangular boxes representing different XAI methods. The central box is labeled "XAI methods in LMs". The branches represent different model architectures:
* **Encoder-only** (Green)
* **Decoder-only** (Red)
* **Encoder-Decoder** (Blue)
The methods branching from these architectures are:
* Feature attribution
* Classifier-based probing
* Parameter-free probing
* Attention-based
* ICL-based (In-Context Learning)
* CoT prompting (Chain-of-Thought prompting)
* Mechanistic Interpretability
* Self-explanation
### Detailed Analysis or Content Details
The diagram can be broken down into three main sections based on the model architecture:
**1. Encoder-only (Green):**
* Branches into four methods: Feature attribution, Classifier-based probing, Parameter-free probing, and Attention-based.
* The Attention-based method further branches into Feature attribution.
**2. Decoder-only (Red):**
* Branches into three methods: Feature attribution, ICL-based, and CoT prompting.
* CoT prompting branches into Mechanistic Interpretability.
**3. Encoder-Decoder (Blue):**
* Branches into three methods: Classifier-based probing, Attention-based, and Self-explanation.
The arrows indicate a flow or relationship between the model architecture and the XAI methods. The diagram suggests that each model architecture supports a variety of XAI techniques, and some techniques can be applied in multiple architectures.
### Key Observations
* Feature attribution and Attention-based methods appear to be versatile, being applicable across all three model architectures.
* Decoder-only models seem to emphasize methods related to prompting and interpretability (ICL-based, CoT prompting, Mechanistic Interpretability).
* The diagram doesn't provide quantitative data, but rather a qualitative overview of the relationships between XAI methods and model architectures.
### Interpretation
The diagram illustrates the diverse landscape of XAI techniques available for understanding Large Language Models. The categorization by model architecture highlights that the choice of XAI method may depend on the underlying model structure. The branching structure suggests that some methods build upon others (e.g., CoT prompting leading to Mechanistic Interpretability). The diagram serves as a useful visual guide for researchers and practitioners interested in applying XAI to LMs, showing the breadth of options available and potential connections between them. The diagram suggests a hierarchical relationship, where the central "XAI methods in LMs" node represents a broad category, and the branches represent increasingly specific techniques. The diagram does not provide any information about the effectiveness or limitations of each method, but rather focuses on their categorization and relationships.