TECHNICAL ASSET FINGERPRINT
81ea363c98b97ffd38c8a166
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
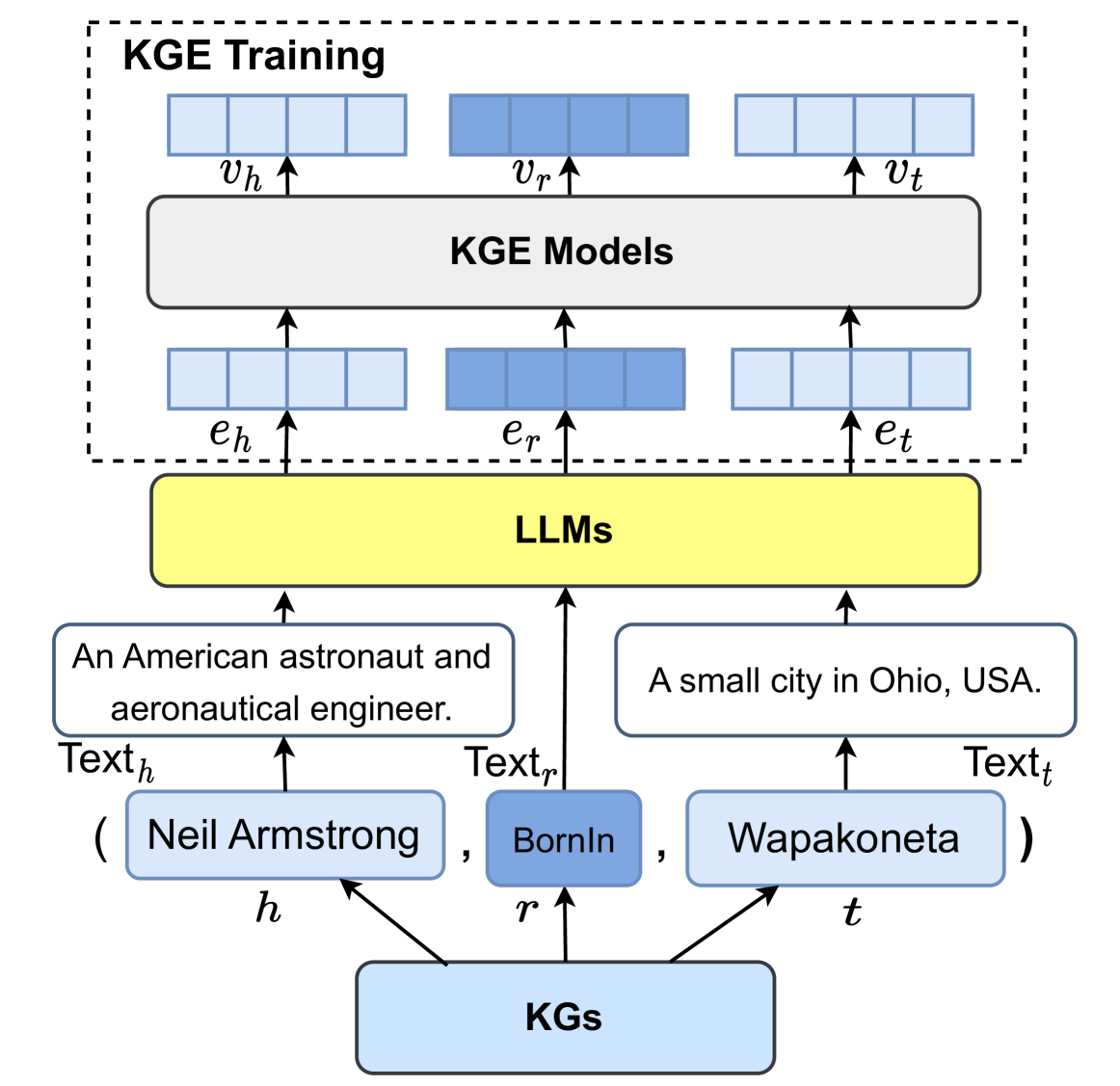
## Diagram: Knowledge Graph Embedding (KGE) Training Pipeline Using LLMs
### Overview
This image is a technical diagram illustrating a pipeline for training Knowledge Graph Embedding (KGE) models. The process uses Large Language Models (LLMs) to generate textual embeddings for entities and relations from a Knowledge Graph (KG), which are then fed into KGE models to produce final vector representations. The diagram uses a specific example triple from a knowledge graph to demonstrate the flow.
### Components and Flow
The diagram is structured vertically, with a bottom-to-top data flow indicated by arrows. It can be segmented into three main regions:
1. **Bottom Region (Input - Knowledge Graph):**
* A central light blue box labeled **"KGs"** (Knowledge Graphs).
* Three arrows point upward from "KGs" to three components representing a knowledge graph triple `(h, r, t)`:
* **Left (h - Head Entity):** A light blue box labeled **"Neil Armstrong"** with the subscript **`h`** below it.
* **Center (r - Relation):** A darker blue box labeled **"BornIn"** with the subscript **`r`** below it.
* **Right (t - Tail Entity):** A light blue box labeled **"Wapakoneta"** with the subscript **`t`** below it.
* The entire triple is enclosed in parentheses: `( Neil Armstrong , BornIn , Wapakoneta )`.
2. **Middle Region (Textual Processing - LLMs):**
* Above the triple, three text descriptions are provided, each with an arrow pointing up to a central yellow box.
* **Left (`Text_h`):** A box containing the text: **"An American astronaut and aeronautical engineer."** An arrow labeled **`Text_h`** points from this box to the LLMs box.
* **Center (`Text_r`):** An arrow labeled **`Text_r`** points directly from the "BornIn" relation box to the LLMs box. No separate descriptive text box is shown for the relation.
* **Right (`Text_t`):** A box containing the text: **"A small city in Ohio, USA."** An arrow labeled **`Text_t`** points from this box to the LLMs box.
* A large, central yellow box labeled **"LLMs"** (Large Language Models) receives the three text inputs (`Text_h`, `Text_r`, `Text_t`).
3. **Top Region (Embedding Generation - KGE Training):**
* This entire section is enclosed in a dashed-line box labeled **"KGE Training"** at the top-left.
* Three arrows point upward from the "LLMs" box to three sets of blue rectangles representing initial embeddings:
* **Left:** A set of four light blue rectangles labeled **`e_h`** (embedding for head).
* **Center:** A set of four darker blue rectangles labeled **`e_r`** (embedding for relation).
* **Right:** A set of four light blue rectangles labeled **`e_t`** (embedding for tail).
* These three embedding sets (`e_h`, `e_r`, `e_t`) are inputs to a central grey box labeled **"KGE Models"**.
* Three arrows point upward from the "KGE Models" box to three final vector representations:
* **Left:** A set of four light blue rectangles labeled **`v_h`** (vector for head).
* **Center:** A set of four darker blue rectangles labeled **`v_r`** (vector for relation).
* **Right:** A set of four light blue rectangles labeled **`v_t`** (vector for tail).
### Detailed Analysis
* **Data Flow:** The process begins with a structured triple `(h, r, t)` from a Knowledge Graph. The head (`h`) and tail (`t`) entities are converted into natural language descriptions (`Text_h`, `Text_t`). The relation (`r`) is also associated with a text label (`Text_r`). These textual representations are processed by LLMs to generate initial dense vector embeddings (`e_h`, `e_r`, `e_t`). These embeddings serve as the input for training specialized KGE models, which then output the final, refined knowledge graph vectors (`v_h`, `v_r`, `v_t`).
* **Color Coding:** A consistent color scheme is used:
* **Light Blue:** Used for head/tail entities (`Neil Armstrong`, `Wapakoneta`), their text descriptions, their initial embeddings (`e_h`, `e_t`), and their final vectors (`v_h`, `v_t`).
* **Darker Blue:** Used exclusively for the relation (`BornIn`), its initial embedding (`e_r`), and its final vector (`v_r`).
* **Yellow:** Highlights the core processing component, the LLMs.
* **Grey:** Represents the KGE Models component.
* **Spatial Grounding:** The "KGE Training" label is in the top-left corner of the dashed box. The "LLMs" box is centrally located, acting as the bridge between textual input and embedding output. The flow is strictly vertical, with no horizontal connections between the parallel processing streams for h, r, and t.
### Key Observations
1. **Hybrid Architecture:** The diagram explicitly shows a pipeline that combines the semantic understanding of LLMs (for processing text) with the structural learning of KGE models (for embedding graph relations).
2. **Asymmetric Treatment:** The relation (`BornIn`) is treated differently from entities. It lacks a descriptive sentence box (`Text_r` is just a label), and its embeddings (`e_r`, `v_r`) are consistently colored differently, suggesting it may be processed or represented in a distinct manner.
3. **Example-Driven:** The use of the specific, well-known triple `(Neil Armstrong, BornIn, Wapakoneta)` serves as a concrete example to ground the abstract technical process.
### Interpretation
This diagram illustrates a method for **enhancing Knowledge Graph Embeddings with semantic knowledge from LLMs**. The core idea is that the rich, pre-trained linguistic knowledge within LLMs can be leveraged to create more meaningful initial embeddings (`e_h`, `e_r`, `e_t`) for graph elements. Instead of starting the KGE training process from random initialization, these LLM-derived embeddings provide a semantically informed starting point.
The pipeline suggests that the textual description of an entity (e.g., "An American astronaut...") contains valuable information that, when encoded by an LLM, can help a KGE model learn better structural representations (`v_h`, `v_r`, `v_t`). This could lead to KGE models that perform better on tasks like link prediction or entity classification, as they benefit from both the graph's structure and the world knowledge embedded in language models. The separation of the "LLMs" and "KGE Models" boxes indicates they are distinct modules, likely pre-trained independently and then integrated in this fashion.
DECODING INTELLIGENCE...