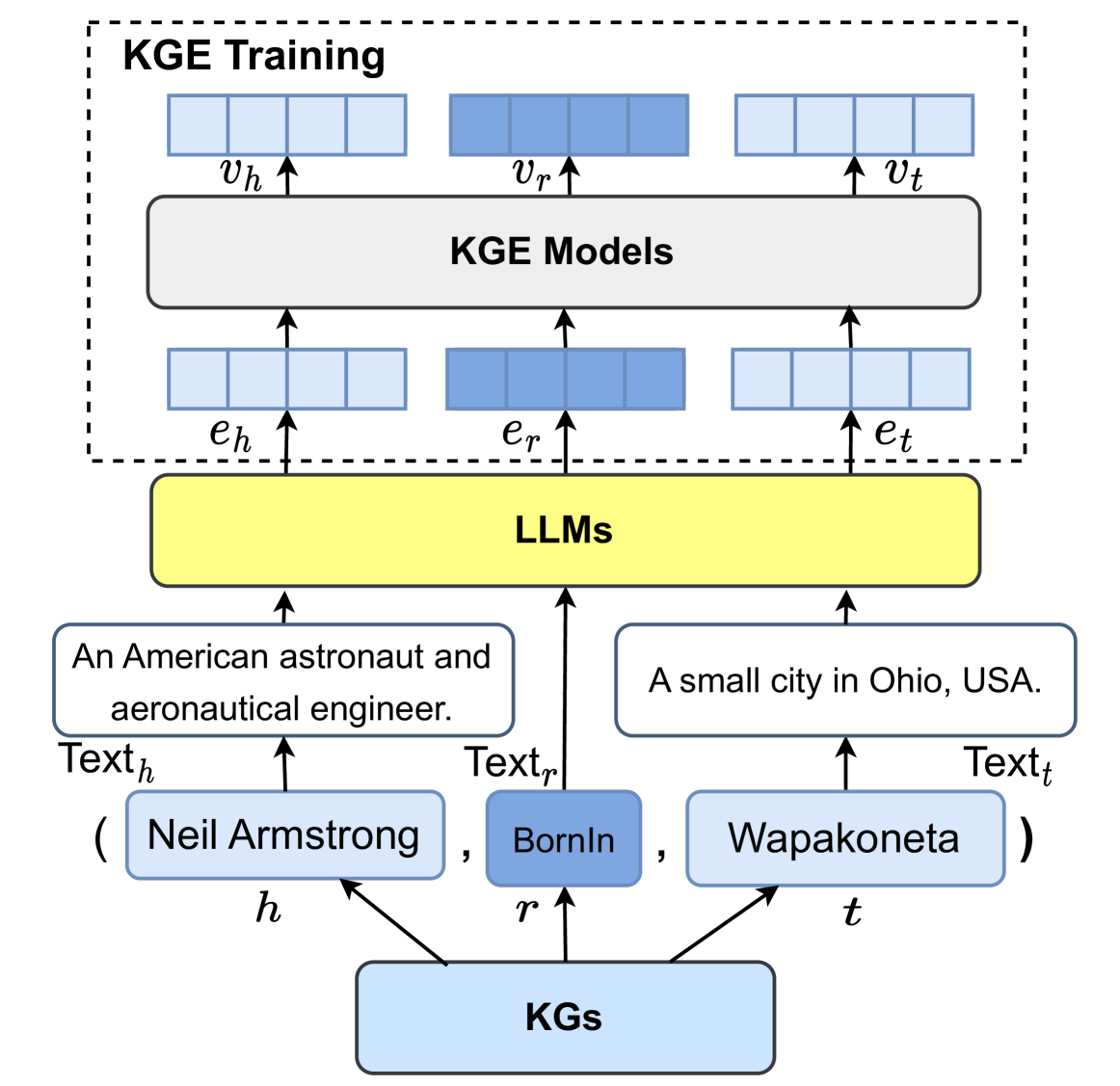
## Diagram: Knowledge Graph Construction Pipeline
### Overview
The diagram illustrates a multi-stage pipeline for constructing knowledge graphs (KGs) from textual data. It shows the flow of information from raw text inputs through various processing stages (KGE Models, KGE Training, LLMs) to structured knowledge graphs. The diagram includes specific examples of entities and relations extracted from text.
### Components/Axes
1. **Top Section (KGE Training & Models):**
- Three blue rectangles labeled `v_h`, `v_r`, `v_t` (likely vector representations)
- Black rectangle labeled "KGE Models"
- Three blue rectangles labeled `e_h`, `e_r`, `e_t` (embedding representations)
- Arrows indicate flow between components
2. **Middle Section (LLMs):**
- Yellow rectangle labeled "LLMs" (Large Language Models)
- Arrows connect to text examples and KG outputs
3. **Bottom Section (KG Examples):**
- Text examples:
- "An American astronaut and aeronautical engineer."
- "A small city in Ohio, USA."
- Structured KG components:
- Entity: Neil Armstrong
- Relation: BornIn
- Entity: Wapakoneta
### Detailed Analysis
1. **Text Processing Flow:**
- Raw text inputs (`Text_h`, `Text_r`, `Text_t`) feed into KGE Models
- KGE Models produce embeddings (`e_h`, `e_r`, `e_t`)
- These embeddings undergo KGE Training to generate vectors (`v_h`, `v_r`, `v_t`)
2. **LLM Integration:**
- LLMs process text examples to extract structured knowledge
- Output includes explicit KG components (entities, relations)
3. **KG Structure:**
- Demonstrates triple-based knowledge representation:
- (Neil Armstrong, BornIn, Wapakoneta)
- Shows hierarchical relationship between text, embeddings, and structured knowledge
### Key Observations
1. **Multi-stage Processing:**
- Text → KGE Models → KGE Training → LLMs → KGs
- Each stage transforms data from unstructured text to structured knowledge
2. **Embedding Relationships:**
- `e_h`/`e_r`/`e_t` embeddings serve as intermediate representations
- Vectors (`v_h`/`v_r`/`v_t`) likely represent trained knowledge graph embeddings
3. **Example Specificity:**
- Concrete examples ground abstract concepts:
- Text → Entity (Neil Armstrong)
- Text → Location (Wapakoneta)
- Relation (BornIn) connecting them
### Interpretation
This diagram represents a knowledge distillation pipeline where:
1. **KGE Models** convert text to semantic embeddings
2. **KGE Training** optimizes these embeddings for knowledge representation
3. **LLMs** bridge the gap between raw text and structured knowledge
4. The final KG structure enables:
- Entity linking
- Relation extraction
- Semantic reasoning
The pipeline demonstrates how modern NLP systems transform unstructured text into machine-readable knowledge graphs, enabling applications like:
- Question answering systems
- Information retrieval
- Entity resolution
- Knowledge-based AI agents
The use of concrete examples (Neil Armstrong/Wapakoneta) suggests this pipeline is designed for real-world knowledge extraction from diverse text sources.