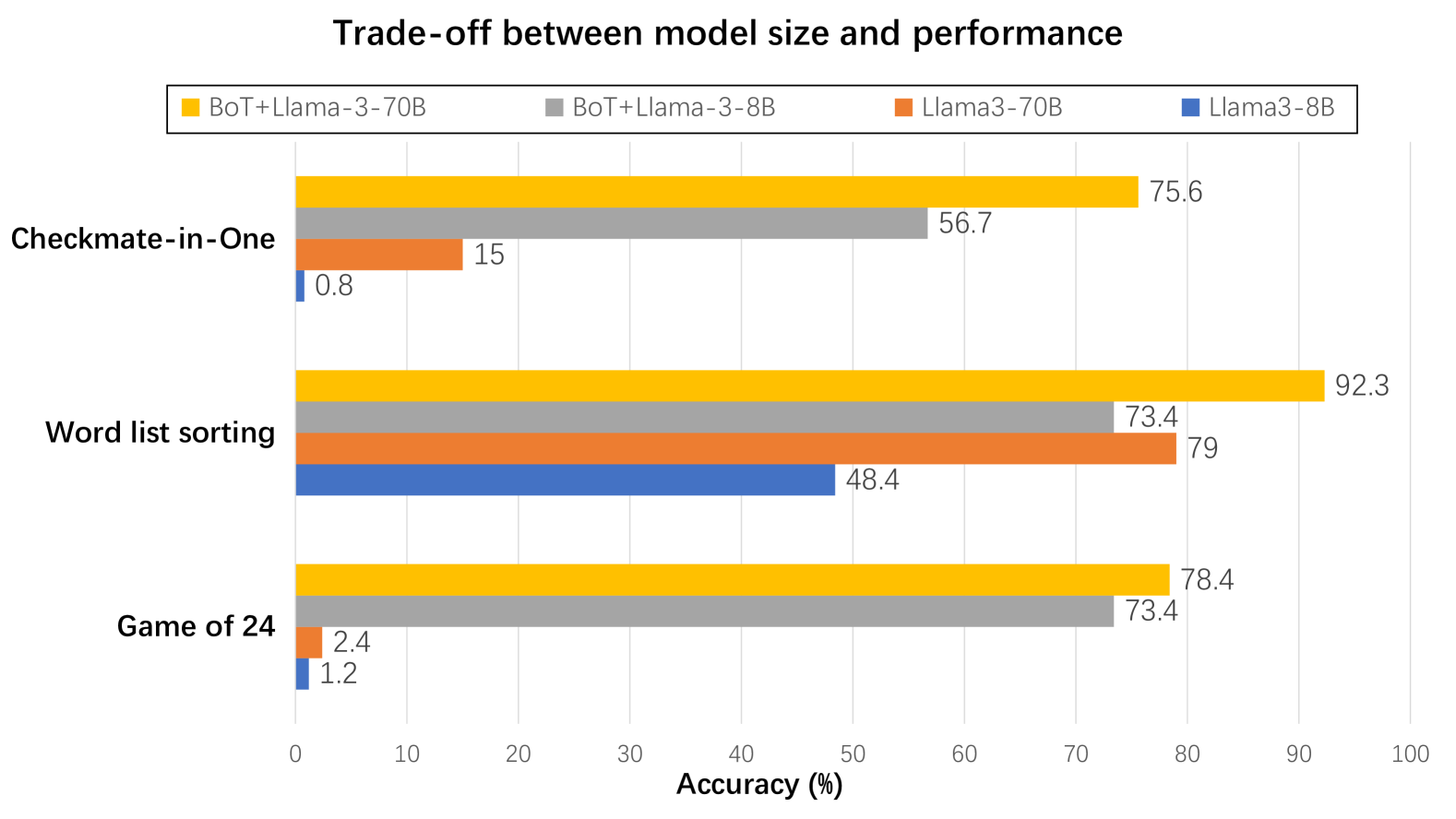
## Bar Chart: Trade-off between model size and performance
### Overview
The image is a horizontal bar chart comparing the accuracy (%) of four different language models (BoT+Llama-3-70B, BoT+Llama-3-8B, Llama3-70B, and Llama3-8B) across three tasks: Checkmate-in-One, Word list sorting, and Game of 24. The x-axis represents accuracy (%), ranging from 0 to 100. The y-axis represents the tasks.
### Components/Axes
* **Title:** Trade-off between model size and performance
* **X-axis:** Accuracy (%) with scale from 0 to 100, incrementing by 10.
* **Y-axis:** Tasks (Checkmate-in-One, Word list sorting, Game of 24)
* **Legend:** Located at the top of the chart.
* Yellow: BoT+Llama-3-70B
* Gray: BoT+Llama-3-8B
* Orange: Llama3-70B
* Blue: Llama3-8B
### Detailed Analysis
The chart presents accuracy scores for each model on each task.
* **Checkmate-in-One:**
* BoT+Llama-3-70B (Yellow): 75.6%
* BoT+Llama-3-8B (Gray): 56.7%
* Llama3-70B (Orange): 15%
* Llama3-8B (Blue): 0.8%
* **Word list sorting:**
* BoT+Llama-3-70B (Yellow): 92.3%
* BoT+Llama-3-8B (Gray): 73.4%
* Llama3-70B (Orange): 79%
* Llama3-8B (Blue): 48.4%
* **Game of 24:**
* BoT+Llama-3-70B (Yellow): 78.4%
* BoT+Llama-3-8B (Gray): 73.4%
* Llama3-70B (Orange): 2.4%
* Llama3-8B (Blue): 1.2%
### Key Observations
* BoT+Llama-3-70B (Yellow) consistently achieves the highest accuracy across all three tasks.
* Llama3-8B (Blue) generally has the lowest accuracy, especially on Checkmate-in-One and Game of 24.
* The performance difference between models is most pronounced on the Checkmate-in-One task.
### Interpretation
The chart illustrates the trade-off between model size and performance. The BoT+Llama-3-70B model, presumably the largest, consistently outperforms the other models in terms of accuracy. The Llama3-8B model, likely the smallest, generally exhibits the lowest accuracy. This suggests that increasing model size (and potentially complexity) leads to improved performance on these tasks. However, the specific architecture (BoT+Llama vs. Llama3) also plays a significant role, as evidenced by the differences between the 70B and 8B versions of each architecture. The Checkmate-in-One task appears to be particularly challenging, highlighting the performance differences between the models. The data suggests that for tasks like Checkmate-in-One, model architecture and size are critical for achieving high accuracy.