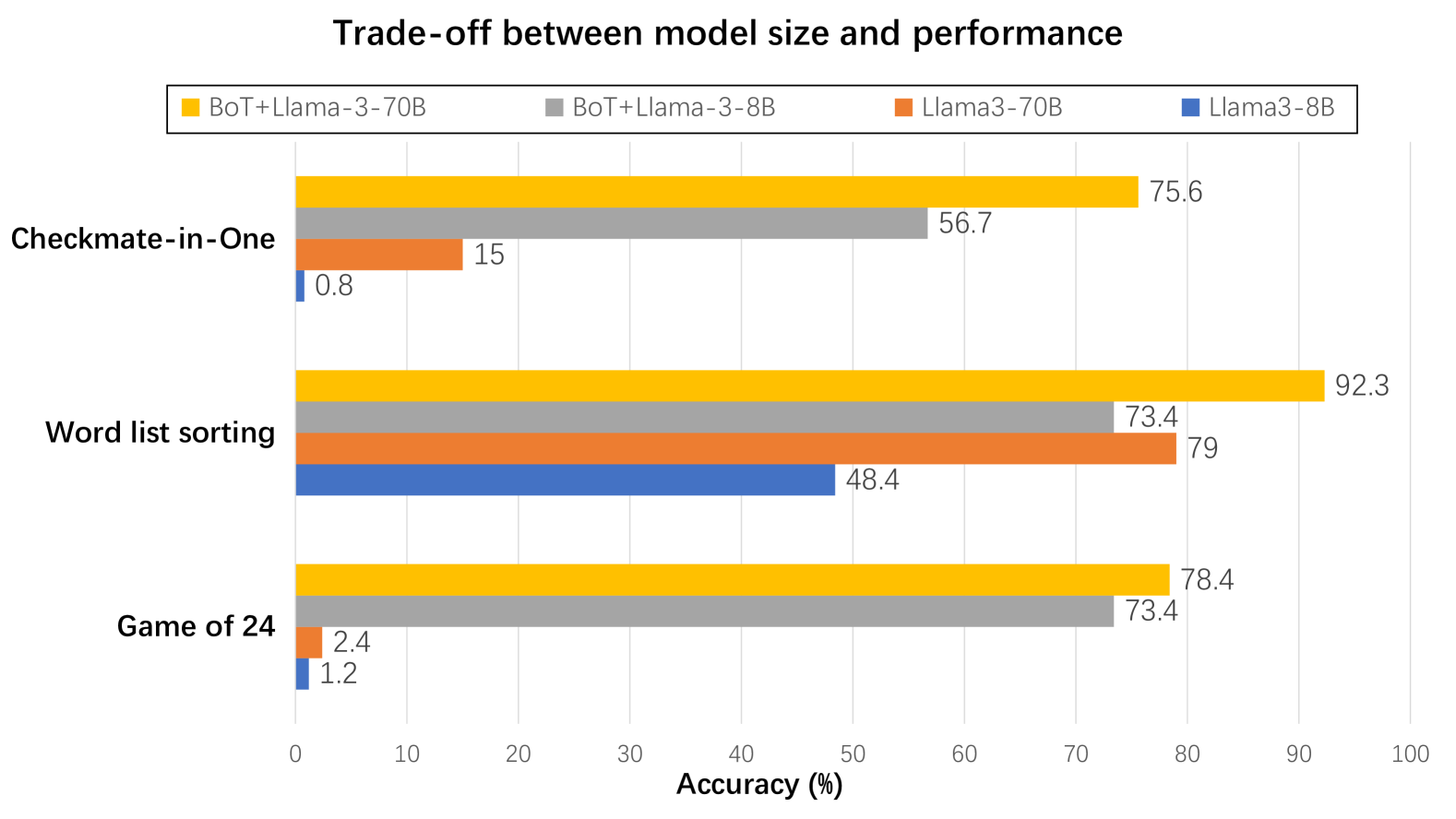
## Horizontal Bar Chart: Trade-off between model size and performance
### Overview
This image is a horizontal grouped bar chart titled "Trade-off between model size and performance." It compares the accuracy (in percentage) of four different language model configurations across three distinct reasoning or puzzle-solving tasks. The chart visually demonstrates how model size (8B vs. 70B parameters) and the addition of a component labeled "BoT" affect performance.
### Components/Axes
* **Title:** "Trade-off between model size and performance" (centered at the top).
* **Legend:** Positioned at the top, below the title. It defines four model configurations by color:
* **Yellow Square:** BoT+Llama-3-70B
* **Gray Square:** BoT+Llama-3-8B
* **Orange Square:** Llama3-70B
* **Blue Square:** Llama3-8B
* **Y-Axis (Vertical):** Lists three task categories. From top to bottom:
1. Checkmate-in-One
2. Word list sorting
3. Game of 24
* **X-Axis (Horizontal):** Labeled "Accuracy (%)". The scale runs from 0 to 100 with major tick marks at every 10-unit interval (0, 10, 20, ..., 100).
* **Data Bars:** For each task, four horizontal bars are grouped together, corresponding to the four models in the legend order (Yellow, Gray, Orange, Blue from top to bottom within each group). The exact accuracy value is printed at the end of each bar.
### Detailed Analysis
**Task 1: Checkmate-in-One**
* **Trend:** Performance varies dramatically. The BoT-enhanced models significantly outperform the base models. The larger model (70B) with BoT performs best.
* **Data Points (Accuracy %):**
* BoT+Llama-3-70B (Yellow): **75.6**
* BoT+Llama-3-8B (Gray): **56.7**
* Llama3-70B (Orange): **15**
* Llama3-8B (Blue): **0.8**
**Task 2: Word list sorting**
* **Trend:** All models show moderate to high accuracy. The BoT+Llama-3-70B model leads. Notably, the base Llama3-70B model outperforms the smaller BoT+Llama-3-8B model.
* **Data Points (Accuracy %):**
* BoT+Llama-3-70B (Yellow): **92.3**
* BoT+Llama-3-8B (Gray): **73.4**
* Llama3-70B (Orange): **79**
* Llama3-8B (Blue): **48.4**
**Task 3: Game of 24**
* **Trend:** A stark divide exists. BoT-enhanced models achieve high accuracy, while base models perform very poorly, near zero.
* **Data Points (Accuracy %):**
* BoT+Llama-3-70B (Yellow): **78.4**
* BoT+Llama-3-8B (Gray): **73.4**
* Llama3-70B (Orange): **2.4**
* Llama3-8B (Blue): **1.2**
### Key Observations
1. **Dominance of BoT Enhancement:** The addition of "BoT" provides a massive performance boost across all tasks, especially for the more complex "Checkmate-in-One" and "Game of 24" tasks, where it elevates accuracy from near-zero to over 50%.
2. **Model Size Impact:** Within the same configuration (with or without BoT), the 70B parameter model consistently outperforms its 8B counterpart. The gap is most pronounced in the base models (e.g., 15% vs. 0.8% in Checkmate-in-One).
3. **Task Difficulty Spectrum:** The tasks appear to have varying inherent difficulty for the base models. "Word list sorting" is the most accessible (48.4% for the smallest model), while "Game of 24" is the most challenging (1.2% for the smallest model).
4. **Notable Anomaly:** In "Word list sorting," the base Llama3-70B (79%) outperforms the smaller BoT+Llama-3-8B (73.4%). This is the only instance where a base model beats a BoT-enhanced model, suggesting the BoT enhancement may be less critical for this specific type of task compared to raw model scale.
### Interpretation
The data strongly suggests that the "BoT" component is a critical factor for enabling these language models to solve complex, multi-step reasoning puzzles ("Checkmate-in-One," "Game of 24"). Without it, even the large 70B model fails almost completely on these tasks. For more structured, possibly linguistic tasks like "Word list sorting," both model scale and the BoT enhancement contribute positively, but scale alone can yield respectable performance.
The chart illustrates a clear trade-off: achieving high performance on advanced reasoning tasks requires not just a large model (70B parameters) but also a specialized enhancement (BoT). The smaller 8B model, when equipped with BoT, can achieve performance comparable to or even exceeding the much larger 70B base model on certain tasks, highlighting the efficiency gain from the BoT method. This implies that architectural or methodological innovations (like BoT) can be as important as, or more important than, simply increasing parameter count for specific capabilities.