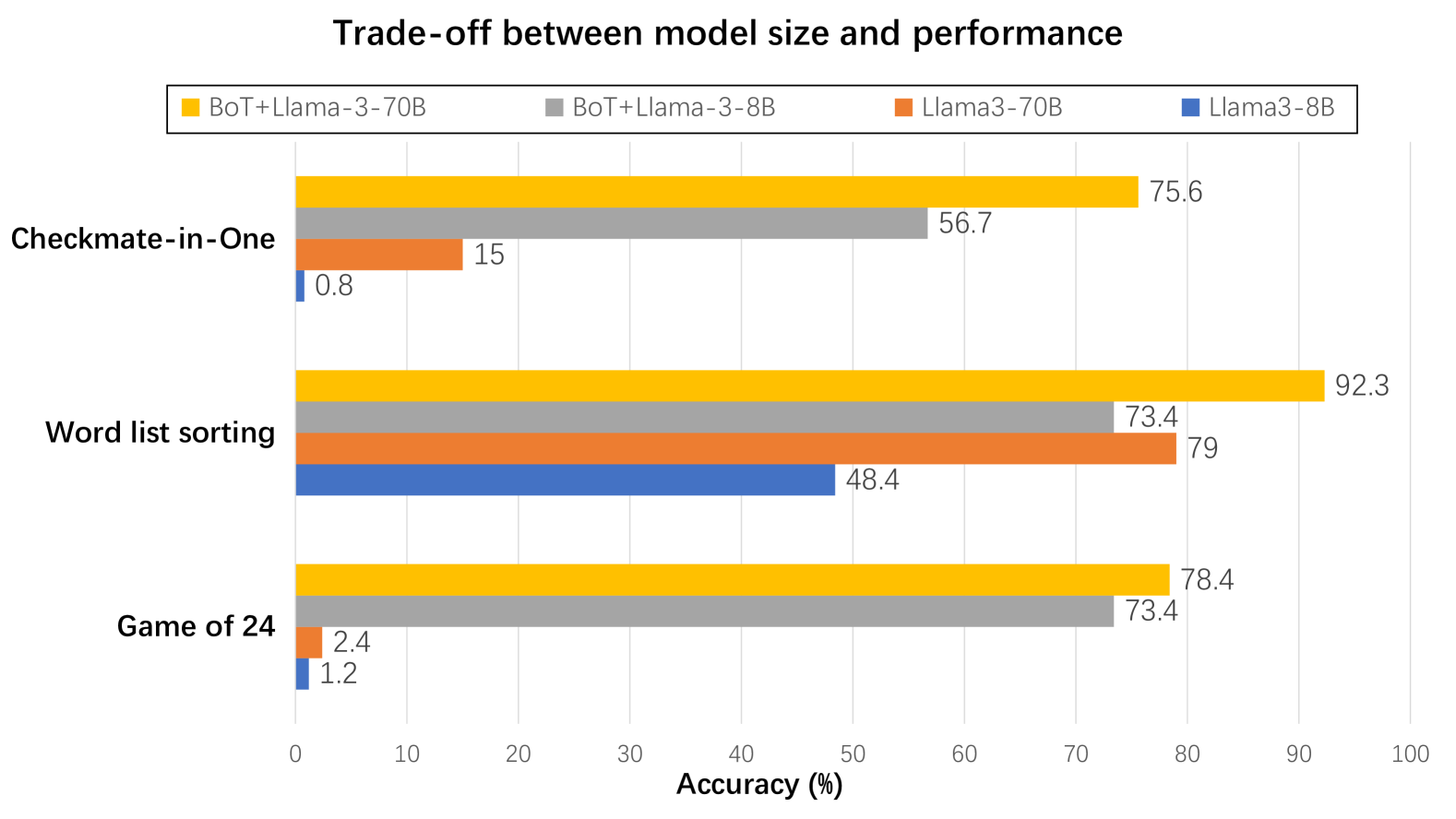
## Bar Chart: Trade-off between model size and performance
### Overview
The chart compares the accuracy performance of four AI models across three tasks: Checkmate-in-One, Word list sorting, and Game of 24. It visualizes the relationship between model size (70B vs 8B parameters) and performance, with special attention to models combining BoT (presumably a base model) with Llama-3 variants.
### Components/Axes
- **X-axis**: Accuracy (%) from 0 to 100 in 10% increments
- **Y-axis**: Three tasks (Checkmate-in-One, Word list sorting, Game of 24)
- **Legend**: Located at top-right, color-coded models:
- Orange: BoT+Llama-3-70B
- Gray: BoT+Llama-3-8B
- Red: Llama3-70B
- Blue: Llama3-8B
### Detailed Analysis
1. **Checkmate-in-One**
- BoT+Llama-3-70B (orange): 75.6%
- BoT+Llama-3-8B (gray): 56.7%
- Llama3-70B (red): 15%
- Llama3-8B (blue): 0.8%
2. **Word list sorting**
- BoT+Llama-3-70B (orange): 92.3%
- BoT+Llama-3-8B (gray): 73.4%
- Llama3-70B (red): 79%
- Llama3-8B (blue): 48.4%
3. **Game of 24**
- BoT+Llama-3-70B (orange): 78.4%
- BoT+Llama-3-8B (gray): 73.4%
- Llama3-70B (red): 2.4%
- Llama3-8B (blue): 1.2%
### Key Observations
1. **Model Size Impact**:
- 70B models consistently outperform 8B versions across all tasks
- Largest gap in Checkmate-in-One (75.6% vs 56.7% for BoT+Llama variants)
2. **BoT+Llama Advantage**:
- BoT+Llama-3-70B achieves highest accuracy in all tasks
- Particularly dominant in Checkmate-in-One (75.6% vs 15% for standalone Llama3-70B)
3. **Performance Drops**:
- Llama3-8B shows dramatic performance decline (e.g., 48.4% vs 73.4% in Word list sorting)
- Smallest models (Llama3-8B) perform near-randomly in Checkmate-in-One (0.8%)
4. **Task Specificity**:
- Word list sorting shows highest overall performance (92.3% peak)
- Game of 24 demonstrates closest performance between model sizes (78.4% vs 73.4%)
### Interpretation
The data reveals a clear trade-off between model size and performance, with larger models (70B) demonstrating significantly better accuracy across all tasks. However, the BoT+Llama combination appears to create a synergistic effect, particularly evident in the Checkmate-in-One task where the 70B version outperforms the standalone Llama3-70B by 60.6 percentage points. This suggests that model architecture optimization (via BoT integration) may be more impactful than raw parameter count alone.
Notably, the performance gap between 70B and 8B models narrows in Word list sorting (18.9% difference) compared to Checkmate-in-One (18.9% difference) and Game of 24 (5% difference), indicating task-dependent scaling efficiency. The near-zero performance of Llama3-8B in Checkmate-in-One highlights potential architectural limitations in smaller models for complex reasoning tasks.