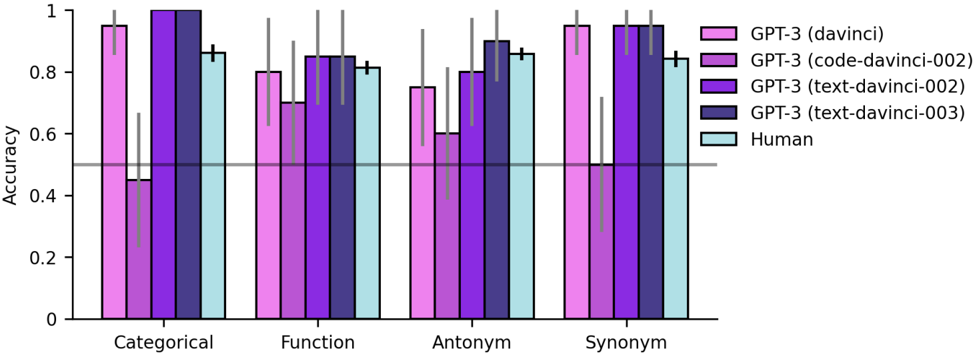
## Bar Chart: GPT-3 and Human Accuracy on Semantic Tasks
### Overview
The image is a bar chart comparing the accuracy of different GPT-3 models and humans on four semantic tasks: Categorical, Function, Antonym, and Synonym. The chart displays accuracy on the y-axis, ranging from 0 to 1, and the semantic tasks on the x-axis. Different colored bars represent the performance of each model and humans. Error bars are included to indicate the variability in the results.
### Components/Axes
* **Y-axis:** "Accuracy", ranging from 0 to 1 in increments of 0.2. A horizontal line is drawn at the 0.5 accuracy level.
* **X-axis:** Categorical, Function, Antonym, Synonym.
* **Legend (Top-Right):**
* Pink: GPT-3 (davinci)
* Purple: GPT-3 (code-davinci-002)
* Dark Purple: GPT-3 (text-davinci-002)
* Navy: GPT-3 (text-davinci-003)
* Light Blue: Human
### Detailed Analysis
Here's a breakdown of the accuracy for each task and model:
* **Categorical:**
* GPT-3 (davinci): Accuracy ~0.45, with error bars extending from ~0.15 to ~0.75.
* GPT-3 (code-davinci-002): Accuracy ~0.95, with error bars extending from ~0.9 to ~1.0.
* GPT-3 (text-davinci-002): Accuracy ~0.98, with error bars extending from ~0.95 to ~1.0.
* GPT-3 (text-davinci-003): Accuracy ~0.99, with error bars extending from ~0.97 to ~1.0.
* Human: Accuracy ~0.85, with error bars extending from ~0.8 to ~0.9.
* **Function:**
* GPT-3 (davinci): Accuracy ~0.7, with error bars extending from ~0.6 to ~0.8.
* GPT-3 (code-davinci-002): Accuracy ~0.8, with error bars extending from ~0.7 to ~0.9.
* GPT-3 (text-davinci-002): Accuracy ~0.85, with error bars extending from ~0.75 to ~0.95.
* GPT-3 (text-davinci-003): Accuracy ~0.85, with error bars extending from ~0.75 to ~0.95.
* Human: Accuracy ~0.85, with error bars extending from ~0.8 to ~0.9.
* **Antonym:**
* GPT-3 (davinci): Accuracy ~0.75, with error bars extending from ~0.65 to ~0.85.
* GPT-3 (code-davinci-002): Accuracy ~0.6, with error bars extending from ~0.5 to ~0.7.
* GPT-3 (text-davinci-002): Accuracy ~0.8, with error bars extending from ~0.7 to ~0.9.
* GPT-3 (text-davinci-003): Accuracy ~0.9, with error bars extending from ~0.8 to ~1.0.
* Human: Accuracy ~0.85, with error bars extending from ~0.8 to ~0.9.
* **Synonym:**
* GPT-3 (davinci): Accuracy ~0.95, with error bars extending from ~0.9 to ~1.0.
* GPT-3 (code-davinci-002): Accuracy ~0.95, with error bars extending from ~0.9 to ~1.0.
* GPT-3 (text-davinci-002): Accuracy ~0.98, with error bars extending from ~0.95 to ~1.0.
* GPT-3 (text-davinci-003): Accuracy ~0.98, with error bars extending from ~0.95 to ~1.0.
* Human: Accuracy ~0.9, with error bars extending from ~0.85 to ~0.95.
### Key Observations
* GPT-3 (davinci) performs significantly worse than other models on the "Categorical" task.
* GPT-3 (text-davinci-003) generally performs the best among the GPT-3 models.
* Human performance is relatively consistent across all tasks, ranging from ~0.85 to ~0.9.
* The error bars suggest some variability in the results, particularly for GPT-3 (davinci) on the "Categorical" task.
### Interpretation
The data suggests that different GPT-3 models have varying strengths and weaknesses when it comes to semantic tasks. The original "davinci" model struggles with categorical tasks, while the fine-tuned "text-davinci-003" model consistently achieves high accuracy across all tasks, often matching or exceeding human performance. The "code-davinci-002" and "text-davinci-002" models also perform well, but not as consistently as "text-davinci-003". The relatively consistent human performance provides a benchmark for evaluating the models. The wide error bars for the "davinci" model on the "Categorical" task indicate that its performance is highly variable and unreliable for this specific task. The horizontal line at 0.5 accuracy serves as a visual indicator of chance performance, highlighting the models that perform significantly better than random guessing.