\n
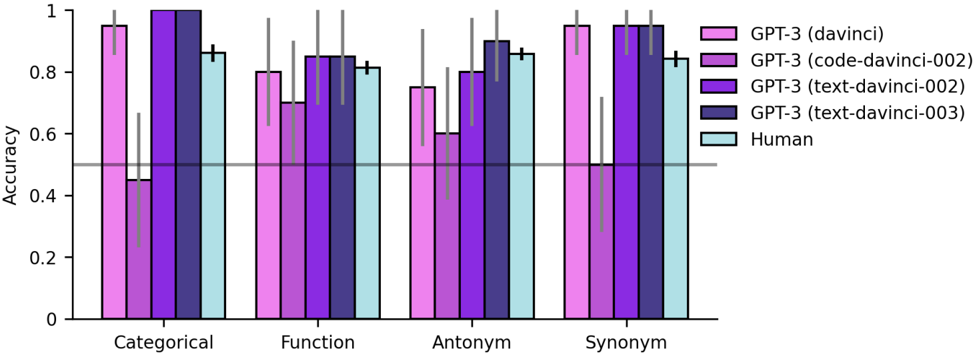
## Bar Chart: Accuracy of Language Models on Semantic Tasks
### Overview
This bar chart compares the accuracy of several GPT-3 models (davinci, code-davinci-002, text-davinci-002, text-davinci-003) and human performance on four semantic tasks: Categorical, Function, Antonym, and Synonym. Accuracy is represented on the y-axis, ranging from 0 to 1, while the x-axis displays the four task types. Each task type has five bars representing the accuracy of each model/human. Error bars are present on top of each bar.
### Components/Axes
* **X-axis:** Semantic Task Type (Categorical, Function, Antonym, Synonym)
* **Y-axis:** Accuracy (Scale: 0 to 1)
* **Legend:**
* GPT-3 (davinci) - Light Purple
* GPT-3 (code-davinci-002) - Medium Purple
* GPT-3 (text-davinci-002) - Dark Purple
* GPT-3 (text-davinci-003) - Very Dark Purple
* Human - Light Blue
* **Error Bars:** Represent the variability or confidence interval around each accuracy score.
### Detailed Analysis
The chart consists of four groups of bars, one for each semantic task. Within each group, there are five bars representing the accuracy of each model/human.
**Categorical:**
* GPT-3 (davinci): Approximately 0.93, with error bar extending to ~0.96
* GPT-3 (code-davinci-002): Approximately 0.85, with error bar extending to ~0.88
* GPT-3 (text-davinci-002): Approximately 0.79, with error bar extending to ~0.82
* GPT-3 (text-davinci-003): Approximately 0.91, with error bar extending to ~0.94
* Human: Approximately 0.88, with error bar extending to ~0.91
**Function:**
* GPT-3 (davinci): Approximately 0.78, with error bar extending to ~0.81
* GPT-3 (code-davinci-002): Approximately 0.81, with error bar extending to ~0.84
* GPT-3 (text-davinci-002): Approximately 0.80, with error bar extending to ~0.83
* GPT-3 (text-davinci-003): Approximately 0.84, with error bar extending to ~0.87
* Human: Approximately 0.83, with error bar extending to ~0.86
**Antonym:**
* GPT-3 (davinci): Approximately 0.65, with error bar extending to ~0.68
* GPT-3 (code-davinci-002): Approximately 0.75, with error bar extending to ~0.78
* GPT-3 (text-davinci-002): Approximately 0.72, with error bar extending to ~0.75
* GPT-3 (text-davinci-003): Approximately 0.81, with error bar extending to ~0.84
* Human: Approximately 0.82, with error bar extending to ~0.85
**Synonym:**
* GPT-3 (davinci): Approximately 0.90, with error bar extending to ~0.93
* GPT-3 (code-davinci-002): Approximately 0.92, with error bar extending to ~0.95
* GPT-3 (text-davinci-002): Approximately 0.91, with error bar extending to ~0.94
* GPT-3 (text-davinci-003): Approximately 0.93, with error bar extending to ~0.96
* Human: Approximately 0.91, with error bar extending to ~0.94
### Key Observations
* GPT-3 (davinci) and GPT-3 (text-davinci-003) generally perform the best on the Categorical and Synonym tasks, often exceeding human accuracy.
* GPT-3 (code-davinci-002) consistently shows good performance across all tasks, often close to or exceeding human accuracy.
* GPT-3 (text-davinci-002) generally has the lowest accuracy among the GPT-3 models.
* The Antonym task consistently shows the lowest accuracy scores for all models, indicating it is the most challenging task.
* Human performance is relatively consistent across all tasks, with a slight dip in accuracy for the Antonym task.
* Error bars suggest that the differences in accuracy between some models are not statistically significant.
### Interpretation
The data suggests that GPT-3 models, particularly davinci and text-davinci-003, are capable of performing well on semantic tasks, sometimes even surpassing human performance. The code-davinci-002 model also demonstrates strong capabilities. The Antonym task appears to be the most difficult for both models and humans, potentially due to the nuanced understanding of word relationships required. The error bars indicate that while some differences in accuracy are apparent, they may not always be statistically significant. This chart demonstrates the progress in natural language understanding achieved by large language models and highlights areas where further improvement is needed, particularly in tasks requiring a deeper understanding of semantic relationships like antonyms. The consistent performance of the human baseline provides a valuable point of comparison for evaluating the models' capabilities.