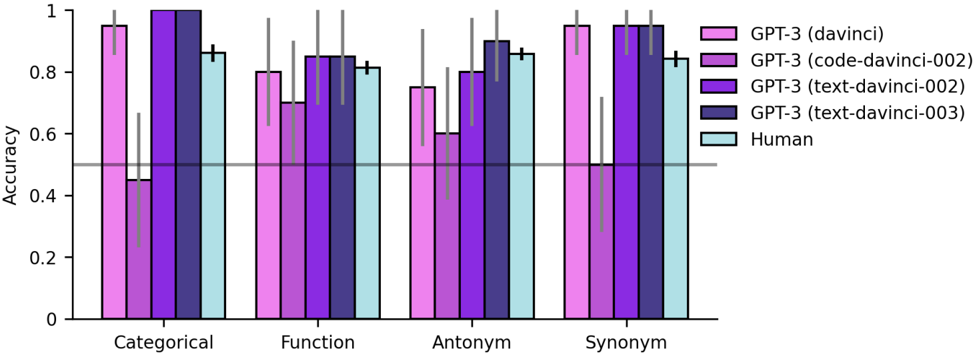
## Bar Chart: Accuracy Comparison of GPT-3 Models vs. Human Performance
### Overview
This is a grouped bar chart comparing the accuracy of four different GPT-3 model variants and human performance across four distinct linguistic or reasoning tasks. The chart includes error bars for each data point and a horizontal reference line at 0.5 accuracy.
### Components/Axes
* **Chart Type:** Grouped bar chart with error bars.
* **Y-Axis:**
* **Label:** "Accuracy"
* **Scale:** Linear, from 0 to 1, with major tick marks at 0, 0.2, 0.4, 0.6, 0.8, and 1.
* **X-Axis:**
* **Categories (from left to right):** "Categorical", "Function", "Antonym", "Synonym".
* **Legend (Top-Right):**
* **Pink Bar:** GPT-3 (davinci)
* **Purple Bar:** GPT-3 (code-davinci-002)
* **Dark Purple Bar:** GPT-3 (text-davinci-002)
* **Navy Blue Bar:** GPT-3 (text-davinci-003)
* **Light Blue Bar:** Human
* **Reference Line:** A solid gray horizontal line at y = 0.5, spanning the width of the chart.
### Detailed Analysis
**Trend Verification & Data Points (Approximate Values):**
1. **Categorical Task:**
* **GPT-3 (davinci) [Pink]:** High accuracy, ~0.95. Error bar extends from ~0.85 to 1.0.
* **GPT-3 (code-davinci-002) [Purple]:** Significantly lower accuracy, ~0.45. Has a very large error bar extending from ~0.25 to ~0.65.
* **GPT-3 (text-davinci-002) [Dark Purple]:** Perfect or near-perfect accuracy, ~1.0. Error bar is minimal.
* **GPT-3 (text-davinci-003) [Navy Blue]:** High accuracy, ~0.85. Error bar extends from ~0.75 to ~0.95.
* **Human [Light Blue]:** High accuracy, ~0.85. Error bar extends from ~0.8 to ~0.9.
2. **Function Task:**
* **GPT-3 (davinci) [Pink]:** Accuracy ~0.8. Error bar from ~0.7 to ~0.9.
* **GPT-3 (code-davinci-002) [Purple]:** Accuracy ~0.7. Error bar from ~0.6 to ~0.8.
* **GPT-3 (text-davinci-002) [Dark Purple]:** Accuracy ~0.85. Error bar from ~0.75 to ~0.95.
* **GPT-3 (text-davinci-003) [Navy Blue]:** Accuracy ~0.85. Error bar from ~0.75 to ~0.95.
* **Human [Light Blue]:** Accuracy ~0.8. Error bar from ~0.75 to ~0.85.
3. **Antonym Task:**
* **GPT-3 (davinci) [Pink]:** Accuracy ~0.75. Error bar from ~0.6 to ~0.9.
* **GPT-3 (code-davinci-002) [Purple]:** Accuracy ~0.6. Error bar from ~0.4 to ~0.8.
* **GPT-3 (text-davinci-002) [Dark Purple]:** Accuracy ~0.8. Error bar from ~0.7 to ~0.9.
* **GPT-3 (text-davinci-003) [Navy Blue]:** Highest accuracy in this group, ~0.9. Error bar from ~0.8 to 1.0.
* **Human [Light Blue]:** Accuracy ~0.85. Error bar from ~0.8 to ~0.9.
4. **Synonym Task:**
* **GPT-3 (davinci) [Pink]:** High accuracy, ~0.95. Error bar from ~0.85 to 1.0.
* **GPT-3 (code-davinci-002) [Purple]:** Low accuracy, ~0.5. Has a very large error bar extending from ~0.3 to ~0.7.
* **GPT-3 (text-davinci-002) [Dark Purple]:** High accuracy, ~0.95. Error bar from ~0.85 to 1.0.
* **GPT-3 (text-davinci-003) [Navy Blue]:** High accuracy, ~0.95. Error bar from ~0.85 to 1.0.
* **Human [Light Blue]:** Accuracy ~0.85. Error bar from ~0.8 to ~0.9.
### Key Observations
1. **Model Performance Hierarchy:** The `text-davinci-002` and `text-davinci-003` models consistently show the highest and most stable accuracy across all four tasks, often matching or exceeding human performance.
2. **High Variability in `code-davinci-002`:** The `code-davinci-002` model exhibits the lowest average accuracy and the largest error bars (indicating high variance or uncertainty) in the "Categorical" and "Synonym" tasks. Its performance is notably poor in these areas compared to other models.
3. **Human Baseline:** Human performance is relatively consistent across all tasks, hovering around 0.85 accuracy with moderate error bars.
4. **Task Difficulty:** The "Antonym" task appears to be the most challenging overall, as it has the lowest peak accuracy (from `text-davinci-003` at ~0.9) and the lowest average performance across models. The "Categorical" and "Synonym" tasks show the widest performance gaps between models.
5. **Reference Line:** The gray line at 0.5 accuracy serves as a baseline. All models and human performance are above this line in all tasks, except for the lower bound of the error bar for `code-davinci-002` in "Categorical" and "Synonym" tasks, which dips below 0.5.
### Interpretation
This chart demonstrates the evolution and specialization of GPT-3 model variants on specific linguistic benchmarks. The data suggests that the `text-davinci` series (versions 002 and 003) represents a significant improvement in both accuracy and reliability over the earlier `davinci` and `code-davinci-002` models for these tasks.
The `code-davinci-002` model's poor and highly variable performance on "Categorical" and "Synonym" tasks is a notable outlier. This could indicate that this model, potentially optimized for code-related functions, is less robust or specialized for certain types of natural language understanding tasks. Its large error bars suggest inconsistent performance across test samples.
The fact that the latest models (`text-davinci-002/003`) meet or exceed human-level accuracy in three of the four tasks (Categorical, Function, Synonym) highlights the rapid advancement in language model capabilities for these specific domains. The "Antonym" task remains a relative challenge for all entities tested, suggesting it may involve more nuanced reasoning or a different type of linguistic knowledge. The chart effectively communicates that model selection is critical, as performance is not uniform across different task types.