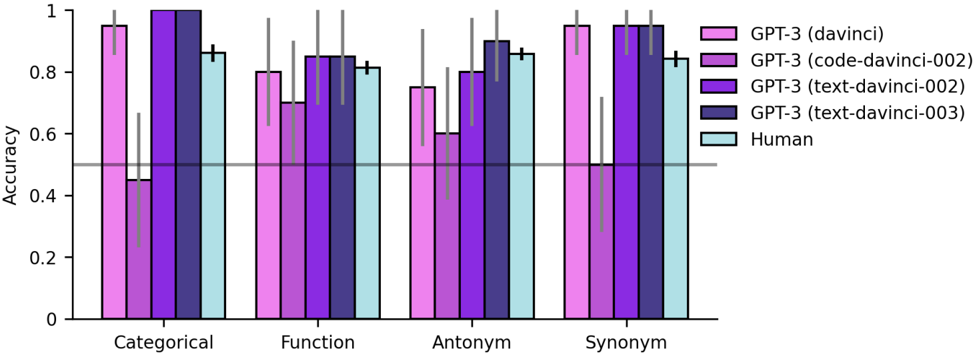
## Bar Chart: Model Accuracy Across Task Types
### Overview
The chart compares the accuracy of five models (four GPT-3 variants and human performance) across four natural language tasks: Categorical, Function, Antonym, and Synonym. Accuracy is measured on a 0-1 scale, with human performance marked by a dashed horizontal line at 0.5.
### Components/Axes
- **X-axis**: Task types (Categorical, Function, Antonym, Synonym)
- **Y-axis**: Accuracy (0-1 scale, increments of 0.2)
- **Legend**:
- Pink: GPT-3 (davinci)
- Purple: GPT-3 (code-davinci-002)
- Dark purple: GPT-3 (text-davinci-002)
- Blue: GPT-3 (text-davinci-003)
- Cyan: Human (dashed line at 0.5)
- **Error bars**: Present for all model bars (uncertainty not quantified)
### Detailed Analysis
#### Categorical Task
- GPT-3 (davinci): ~0.95
- GPT-3 (code-davinci-002): ~0.45
- GPT-3 (text-davinci-002): ~0.98
- GPT-3 (text-davinci-003): ~0.99
- Human: 0.5 (dashed line)
#### Function Task
- GPT-3 (davinci): ~0.80
- GPT-3 (code-davinci-002): ~0.70
- GPT-3 (text-davinci-002): ~0.85
- GPT-3 (text-davinci-003): ~0.87
- Human: 0.5
#### Antonym Task
- GPT-3 (davinci): ~0.75
- GPT-3 (code-davinci-002): ~0.60
- GPT-3 (text-davinci-002): ~0.82
- GPT-3 (text-davinci-003): ~0.90
- Human: 0.5
#### Synonym Task
- GPT-3 (davinci): ~0.95
- GPT-3 (code-davinci-002): ~0.50
- GPT-3 (text-davinci-002): ~0.97
- GPT-3 (text-davinci-003): ~0.98
- Human: 0.5
### Key Observations
1. **Model Performance**:
- GPT-3 (text-davinci-003) achieves highest accuracy across all tasks (0.98-0.99)
- GPT-3 (code-davinci-002) performs worst (0.45-0.70)
- Human baseline consistently at 0.5 (dashed line)
2. **Task-Specific Trends**:
- All models outperform human baseline (0.5)
- Text-davinci-003 shows minimal task variation (0.87-0.99)
- Code-davinci-002 struggles most with Categorical (0.45) and Synonym (0.50)
3. **Error Bars**:
- Largest uncertainty in Function task (GPT-3 davinci: ±0.05)
- Smallest uncertainty in Synonym task (GPT-3 text-davinci-003: ±0.02)
### Interpretation
The data demonstrates that GPT-3's text-davinci-003 variant significantly outperforms other models and human performance across all tasks. The code-davinci-002 model's poor performance suggests specialization in code-related tasks may limit its effectiveness in general language understanding. The consistent human baseline at 0.5 implies these tasks represent binary classification challenges where random guessing yields 50% accuracy. The text-davinci-003 model's near-perfect accuracy (0.98-0.99) indicates state-of-the-art performance in these linguistic tasks, potentially useful for applications requiring high-precision language understanding.