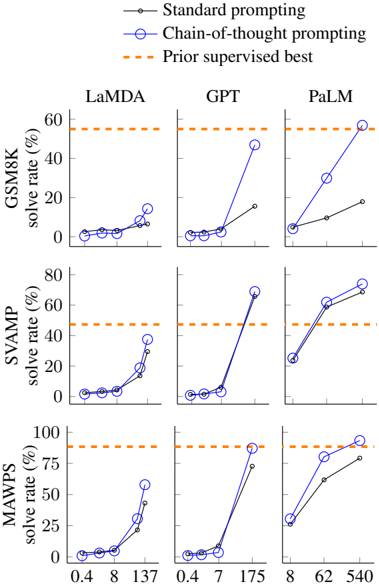
## Chart: Model Performance Comparison
### Overview
The image presents a series of line graphs comparing the performance of different language models (LaMDA, GPT, PaLM) on three datasets (GSM8K, SVAMP, MAWPS). The graphs show the "solve rate (%)" for each model using two prompting strategies: "Standard prompting" and "Chain-of-thought prompting". A horizontal dashed line indicates the "Prior supervised best" performance for each dataset.
### Components/Axes
* **Title:** Model Performance Comparison
* **Y-axis:** "solve rate (%)", with a scale from 0 to 60 for GSM8K, 0 to 80 for SVAMP, and 0 to 100 for MAWPS.
* **X-axis:** Model-specific input sizes or parameters. The values vary for each model:
* LaMDA: 0.4, 8, 137
* GPT: 0.4, 7, 175
* PaLM: 8, 62, 540
* **Models:** LaMDA, GPT, PaLM (arranged horizontally)
* **Datasets:** GSM8K, SVAMP, MAWPS (arranged vertically)
* **Legend (Top-Right):**
* Black line with circles: "Standard prompting"
* Blue line with circles: "Chain-of-thought prompting"
* Orange dashed line: "Prior supervised best"
### Detailed Analysis
**GSM8K Dataset:**
* **LaMDA:**
* Standard prompting: Solve rate increases slightly from approximately 2% to 5% as the input size increases from 0.4 to 137.
* Chain-of-thought prompting: Solve rate increases slightly from approximately 2% to 12% as the input size increases from 0.4 to 137.
* Prior supervised best: Approximately 57%.
* **GPT:**
* Standard prompting: Solve rate increases from approximately 2% to 15% as the input size increases from 0.4 to 175.
* Chain-of-thought prompting: Solve rate increases sharply from approximately 2% to 47% as the input size increases from 0.4 to 175.
* Prior supervised best: Approximately 57%.
* **PaLM:**
* Standard prompting: Solve rate increases from approximately 8% to 18% as the input size increases from 8 to 540.
* Chain-of-thought prompting: Solve rate increases sharply from approximately 10% to 58% as the input size increases from 8 to 540.
* Prior supervised best: Approximately 57%.
**SVAMP Dataset:**
* **LaMDA:**
* Standard prompting: Solve rate increases slightly from approximately 5% to 30% as the input size increases from 0.4 to 137.
* Chain-of-thought prompting: Solve rate increases from approximately 5% to 40% as the input size increases from 0.4 to 137.
* Prior supervised best: Approximately 48%.
* **GPT:**
* Standard prompting: Solve rate increases from approximately 3% to 10% as the input size increases from 0.4 to 175.
* Chain-of-thought prompting: Solve rate increases sharply from approximately 3% to 68% as the input size increases from 0.4 to 175.
* Prior supervised best: Approximately 48%.
* **PaLM:**
* Standard prompting: Solve rate increases from approximately 25% to 60% as the input size increases from 8 to 540.
* Chain-of-thought prompting: Solve rate increases from approximately 30% to 70% as the input size increases from 8 to 540.
* Prior supervised best: Approximately 48%.
**MAWPS Dataset:**
* **LaMDA:**
* Standard prompting: Solve rate increases from approximately 2% to 30% as the input size increases from 0.4 to 137.
* Chain-of-thought prompting: Solve rate increases from approximately 2% to 55% as the input size increases from 0.4 to 137.
* Prior supervised best: Approximately 90%.
* **GPT:**
* Standard prompting: Solve rate increases from approximately 2% to 75% as the input size increases from 0.4 to 175.
* Chain-of-thought prompting: Solve rate increases sharply from approximately 2% to 80% as the input size increases from 0.4 to 175.
* Prior supervised best: Approximately 90%.
* **PaLM:**
* Standard prompting: Solve rate increases from approximately 5% to 75% as the input size increases from 8 to 540.
* Chain-of-thought prompting: Solve rate increases from approximately 5% to 90% as the input size increases from 8 to 540.
* Prior supervised best: Approximately 90%.
### Key Observations
* Chain-of-thought prompting generally outperforms standard prompting across all models and datasets.
* The performance gain from chain-of-thought prompting is more significant for GPT and PaLM compared to LaMDA.
* For all models and datasets, performance generally increases with input size.
* PaLM with chain-of-thought prompting reaches the "Prior supervised best" performance on the MAWPS dataset.
* GPT with chain-of-thought prompting nearly reaches the "Prior supervised best" performance on the MAWPS dataset.
### Interpretation
The data suggests that "Chain-of-thought prompting" is a more effective strategy for improving the problem-solving capabilities of language models compared to "Standard prompting". The models GPT and PaLM benefit more from this strategy than LaMDA, indicating that their architectures are better suited to leverage the chain-of-thought approach. The increase in performance with input size suggests that larger models or more context can lead to better results. The fact that PaLM and GPT with chain-of-thought prompting approach or exceed the "Prior supervised best" performance on some datasets indicates that these models, when combined with effective prompting strategies, can achieve state-of-the-art results without relying on extensive supervised training.