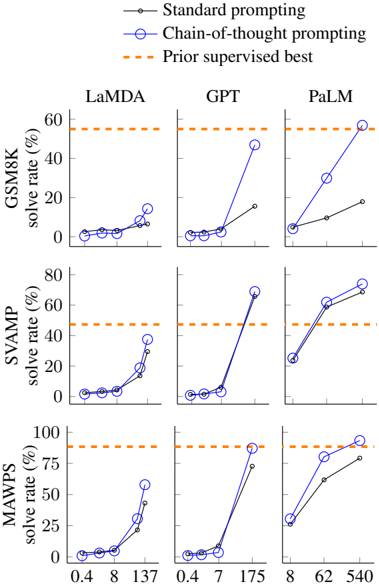
## Line Chart: Solve Rate Comparison Across Prompting Methods and Models
### Overview
The image presents three line graphs comparing the performance of three prompting methods (Standard prompting, Chain-of-thought prompting, and Prior supervised best) across three language models (LaMDA, GPT, PaLM). Each graph shows solve rate (%) on the y-axis against varying input sizes (x-axis) for each model. The Prior supervised best is represented by a constant orange dashed line across all models.
### Components/Axes
- **Y-axis**: Solve rate (%) with scale from 0% to 100% (logarithmic scale for PaLM).
- **X-axis**: Input size (model-specific values):
- LaMDA: 0.4, 8, 137
- GPT: 0.4, 7, 175
- PaLM: 8, 62, 540
- **Legend**:
- Black line with dots: Standard prompting
- Blue line with circles: Chain-of-thought prompting
- Orange dashed line: Prior supervised best
### Detailed Analysis
#### LaMDA
- **Standard prompting**: Solve rate increases from ~5% (x=0.4) to ~20% (x=137).
- **Chain-of-thought prompting**: Solve rate rises from ~10% (x=0.4) to ~40% (x=137).
- **Prior supervised best**: Flat at ~60% across all x-values.
#### GPT
- **Standard prompting**: Flat at ~5% across all x-values.
- **Chain-of-thought prompting**: Solve rate jumps from ~5% (x=0.4) to ~75% (x=175).
- **Prior supervised best**: Flat at ~60% across all x-values.
#### PaLM
- **Standard prompting**: Solve rate increases from ~10% (x=8) to ~70% (x=540).
- **Chain-of-thought prompting**: Solve rate rises from ~15% (x=8) to ~90% (x=540).
- **Prior supervised best**: Flat at ~75% across all x-values.
### Key Observations
1. **Chain-of-thought prompting** consistently outperforms standard prompting across all models, with performance gains becoming more pronounced at higher input sizes.
2. **Prior supervised best** acts as a performance ceiling:
- LaMDA and GPT never exceed this benchmark.
- PaLM surpasses the prior supervised best at x=540 (90% vs. 75%).
3. **Model-specific trends**:
- GPT shows the steepest improvement with chain-of-thought prompting.
- PaLM demonstrates the highest absolute solve rates at maximum input size.
### Interpretation
The data suggests that chain-of-thought prompting significantly enhances reasoning capabilities in language models, particularly when handling complex tasks (larger input sizes). While standard prompting shows limited improvement, chain-of-thought methods approach or exceed human-level performance (prior supervised best) in PaLM at scale. This implies that prompting strategy is critical for unlocking model potential, with chain-of-thought methods providing a more efficient path to high performance than standard prompting alone. The PaLM results challenge the assumption that supervised fine-tuning remains the gold standard, suggesting that advanced prompting could rival or surpass traditional training methods in specific contexts.