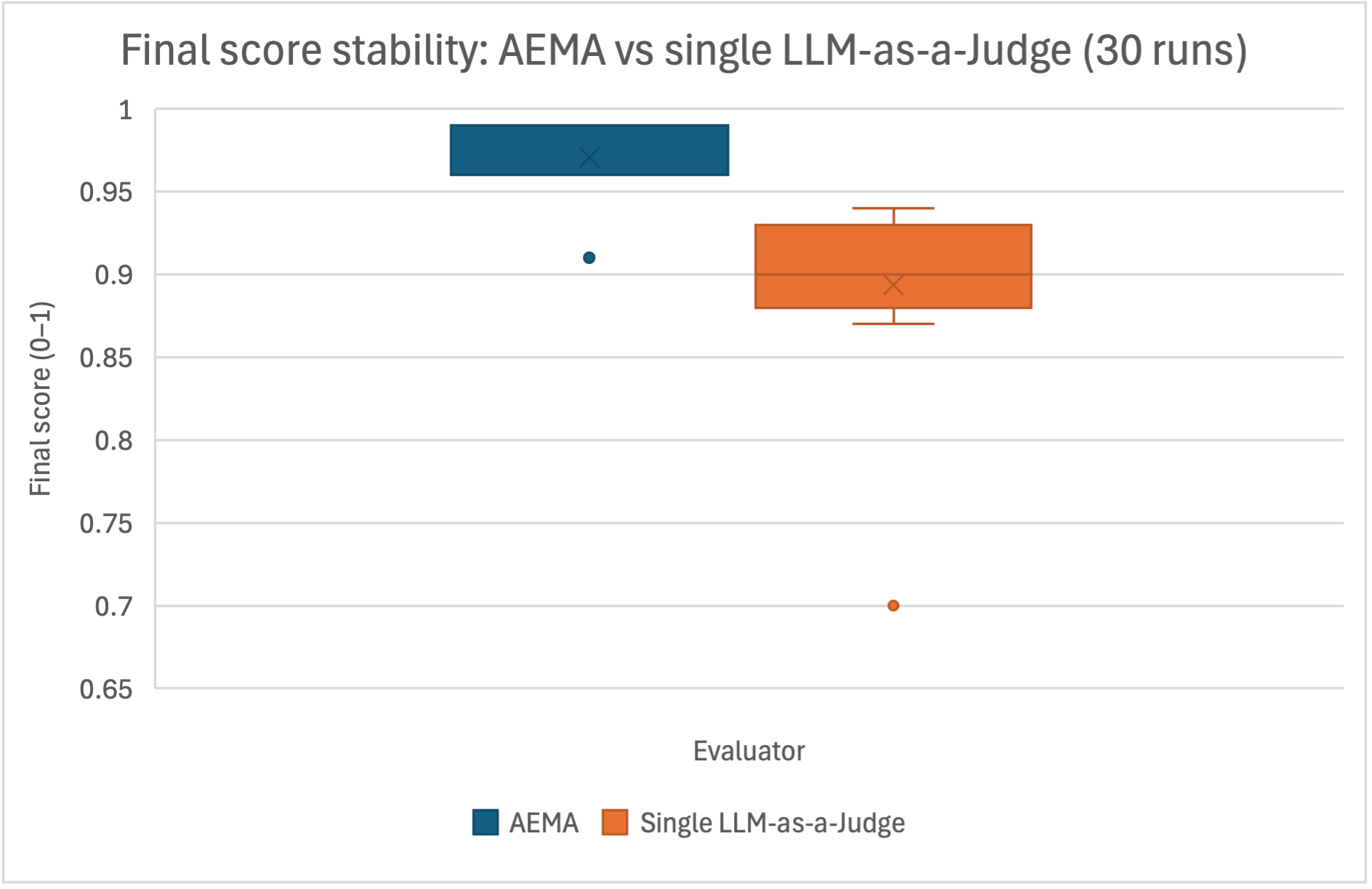
## Box Plot: Final score stability: AEMA vs single LLM-as-a-Judge (30 runs)
### Overview
The image presents a comparative box plot analysis of final score stability between two evaluators: AEMA and Single LLM-as-a-Judge, based on 30 runs. The y-axis represents final scores on a 0–1 scale, while the x-axis categorizes results by evaluator type.
### Components/Axes
- **X-axis (Evaluator)**:
- Categories: "AEMA" (blue) and "Single LLM-as-a-Judge" (orange)
- Legend: Located at the bottom, explicitly mapping colors to evaluators
- **Y-axis (Final score)**:
- Scale: 0.65 to 1.0 in increments of 0.05
- Label: "Final score (0–1)"
- **Plot Elements**:
- Box plots for both evaluators
- Median lines (marked with "X")
- Whiskers indicating interquartile ranges
- Outlier markers (dots)
### Detailed Analysis
1. **AEMA (Blue)**:
- Median score: ~0.95 (marked by "X")
- Interquartile range: ~0.92 to 0.98
- Outlier: Single data point at ~0.91 (below the lower whisker)
- Distribution: Tight clustering around the median
2. **Single LLM-as-a-Judge (Orange)**:
- Median score: ~0.89 (marked by "X")
- Interquartile range: ~0.87 to 0.93
- Outlier: Single data point at ~0.70 (below the lower whisker)
- Distribution: Wider spread compared to AEMA
### Key Observations
- AEMA demonstrates higher median scores (~0.95 vs. ~0.89) and tighter score distribution.
- Single LLM-as-a-Judge shows greater variability, with a lower median and a notable outlier at 0.70.
- Both evaluators exhibit outliers, but the Single LLM-as-a-Judge's outlier is more extreme relative to its distribution.
### Interpretation
The data suggests AEMA provides more stable and higher-performing evaluations compared to the Single LLM-as-a-Judge approach. The tighter interquartile range for AEMA indicates consistency, while the Single LLM-as-a-Judge's wider spread and lower median highlight potential instability. The outlier at 0.70 for the Single LLM-as-a-Judge may represent an anomalous run, though its cause (e.g., data quality, model configuration) is not specified. These results imply AEMA could be preferable for applications requiring reliable score stability, whereas the Single LLM-as-a-Judge might require further refinement or validation.