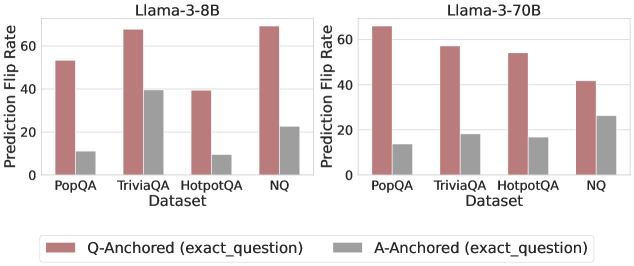
## Bar Chart: Prediction Flip Rate Comparison for Llama-3-8B and Llama-3-70B Models
### Overview
The image is a grouped bar chart comparing prediction flip rates (in percentage) for two language models, **Llama-3-8B** and **Llama-3-70B**, across four datasets: **PopQA**, **TriviaQA**, **HotpotQA**, and **NQ**. Two anchoring methods are compared: **Q-Anchored (exact_question)** (red bars) and **A-Anchored (exact_question)** (gray bars).
### Components/Axes
- **X-axis**: Datasets (PopQA, TriviaQA, HotpotQA, NQ).
- **Y-axis**: Prediction Flip Rate (%) ranging from 0 to 70% in 20% increments.
- **Legend**:
- Red: Q-Anchored (exact_question)
- Gray: A-Anchored (exact_question)
- **Models**:
- Llama-3-8B (left chart)
- Llama-3-70B (right chart)
### Detailed Analysis
#### Llama-3-8B (Left Chart)
- **PopQA**:
- Q-Anchored: ~55%
- A-Anchored: ~10%
- **TriviaQA**:
- Q-Anchored: ~65%
- A-Anchored: ~40%
- **HotpotQA**:
- Q-Anchored: ~40%
- A-Anchored: ~10%
- **NQ**:
- Q-Anchored: ~65%
- A-Anchored: ~20%
#### Llama-3-70B (Right Chart)
- **PopQA**:
- Q-Anchored: ~65%
- A-Anchored: ~15%
- **TriviaQA**:
- Q-Anchored: ~55%
- A-Anchored: ~20%
- **HotpotQA**:
- Q-Anchored: ~50%
- A-Anchored: ~15%
- **NQ**:
- Q-Anchored: ~45%
- A-Anchored: ~25%
### Key Observations
1. **Q-Anchored Consistently Outperforms A-Anchored**:
- Across all datasets and models, Q-Anchored flip rates are significantly higher than A-Anchored rates.
- Example: Llama-3-8B on NQ shows a 65% (Q) vs. 20% (A) gap.
2. **Model Size Impact**:
- Llama-3-70B generally has lower flip rates than Llama-3-8B, particularly in **NQ** (45% vs. 65% for Q-Anchored).
3. **Dataset Variability**:
- **NQ** has the highest Q-Anchored rates for both models.
- **HotpotQA** shows the largest drop between Q and A anchoring for Llama-3-8B (~30% difference).
### Interpretation
- **Anchoring Method Effectiveness**: Q-Anchored (exact_question) demonstrates superior performance, suggesting that precise question alignment improves prediction stability.
- **Model Scaling Trade-offs**: While Llama-3-70B reduces flip rates compared to Llama-3-8B, the gap between anchoring methods narrows, implying diminishing returns in larger models for Q-Anchored benefits.
- **Dataset-Specific Behavior**: The **NQ** dataset’s high Q-Anchored rates may reflect its question complexity or structure, which aligns better with exact anchoring.
### Spatial Grounding & Trend Verification
- **Legend Placement**: Bottom-left, clearly labeled with color-coded anchors.
- **Bar Trends**:
- Q-Anchored bars slope upward relative to A-Anchored across all datasets.
- Llama-3-70B’s bars are shorter than Llama-3-8B’s, confirming lower flip rates.
- **Color Consistency**: Red (Q) and gray (A) bars match legend labels without ambiguity.
### Content Details
- **Approximate Values**:
- Llama-3-8B:
- PopQA: Q=55%, A=10%
- TriviaQA: Q=65%, A=40%
- HotpotQA: Q=40%, A=10%
- NQ: Q=65%, A=20%
- Llama-3-70B:
- PopQA: Q=65%, A=15%
- TriviaQA: Q=55%, A=20%
- HotpotQA: Q=50%, A=15%
- NQ: Q=45%, A=25%
### Notable Outliers
- **Llama-3-8B on TriviaQA**: A-Anchored rate (~40%) is unusually high compared to other datasets, suggesting dataset-specific model behavior.
- **Llama-3-70B on NQ**: Q-Anchored rate (~45%) is notably lower than Llama-3-8B’s (~65%), highlighting model size’s impact on performance.
### Final Notes
The chart underscores the importance of anchoring methods in model reliability, with Q-Anchored outperforming A-Anchored across all scenarios. Model scaling improves performance but does not eliminate the anchoring gap, indicating architectural or training differences between the two models.