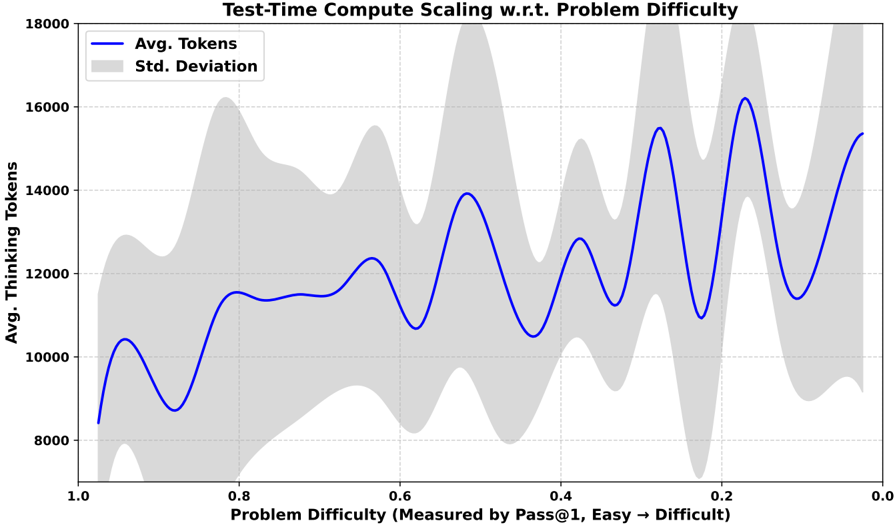
## Line Chart: Test-Time Compute Scaling w.r.t. Problem Difficulty
### Overview
The chart illustrates the relationship between problem difficulty (measured by Pass@1, with 1.0 representing "Easy" and 0.0 representing "Difficult") and the average number of thinking tokens required, along with the standard deviation of token usage. The x-axis decreases from 1.0 (easy) to 0.0 (difficult), while the y-axis ranges from 8,000 to 18,000 tokens. A blue line represents the average tokens, and a gray shaded area indicates the standard deviation.
### Components/Axes
- **X-Axis**: "Problem Difficulty (Measured by Pass@1, Easy → Difficult)"
- Scale: 1.0 (left) to 0.0 (right), with markers at 1.0, 0.8, 0.6, 0.4, 0.2, 0.0.
- **Y-Axis**: "Avg. Thinking Tokens"
- Scale: 8,000 (bottom) to 18,000 (top), with markers at 8,000, 10,000, 12,000, 14,000, 16,000, 18,000.
- **Legend**:
- Top-left corner.
- Blue line: "Avg. Tokens"
- Gray shaded area: "Std. Deviation"
- **Grid**: Dotted lines for alignment.
### Detailed Analysis
- **Avg. Tokens (Blue Line)**:
- The line starts at ~8,500 tokens at x=1.0 (easy) and increases to ~16,000 tokens at x=0.0 (difficult).
- Peaks occur at x=0.6 (~12,000 tokens), x=0.4 (~13,000 tokens), x=0.2 (~15,000 tokens), and x=0.0 (~16,000 tokens).
- The trend shows a general upward slope as problem difficulty decreases (x-axis moves right).
- **Std. Deviation (Gray Shaded Area)**:
- The shaded area is widest at x=1.0 (~2,000 tokens) and narrowest at x=0.0 (~1,000 tokens).
- Variability decreases as problem difficulty increases (x-axis moves left).
### Key Observations
1. **Inverse Relationship**: As problem difficulty decreases (x-axis moves right), the average number of tokens required increases.
2. **Peaks in Token Usage**: Notable spikes in token usage occur at x=0.6, 0.4, 0.2, and 0.0, suggesting specific difficulty thresholds where compute scaling is more pronounced.
3. **Standard Deviation Trends**: The standard deviation (gray area) is largest at higher difficulty levels (x=1.0) and smallest at lower difficulty levels (x=0.0), indicating greater variability in token usage for easier problems.
### Interpretation
The data suggests that **test-time compute scaling is inversely related to problem difficulty**. Easier problems (higher x-values) require fewer tokens on average but exhibit higher variability in token usage, while harder problems (lower x-values) demand more tokens with tighter variability. The peaks in token usage at specific difficulty levels (e.g., x=0.6, 0.4) may indicate critical points where the model's computational demands spike, possibly due to complex reasoning or resource-intensive operations. The narrowing standard deviation at lower difficulty levels implies that the model's performance becomes more consistent as problems become harder, potentially reflecting optimized or constrained processing strategies.
**Note**: The x-axis direction (1.0 → 0.0) is unconventional, as difficulty typically increases from 0 to 1. This reversal may reflect a specific metric (e.g., Pass@1 score) where higher values correspond to easier problems.