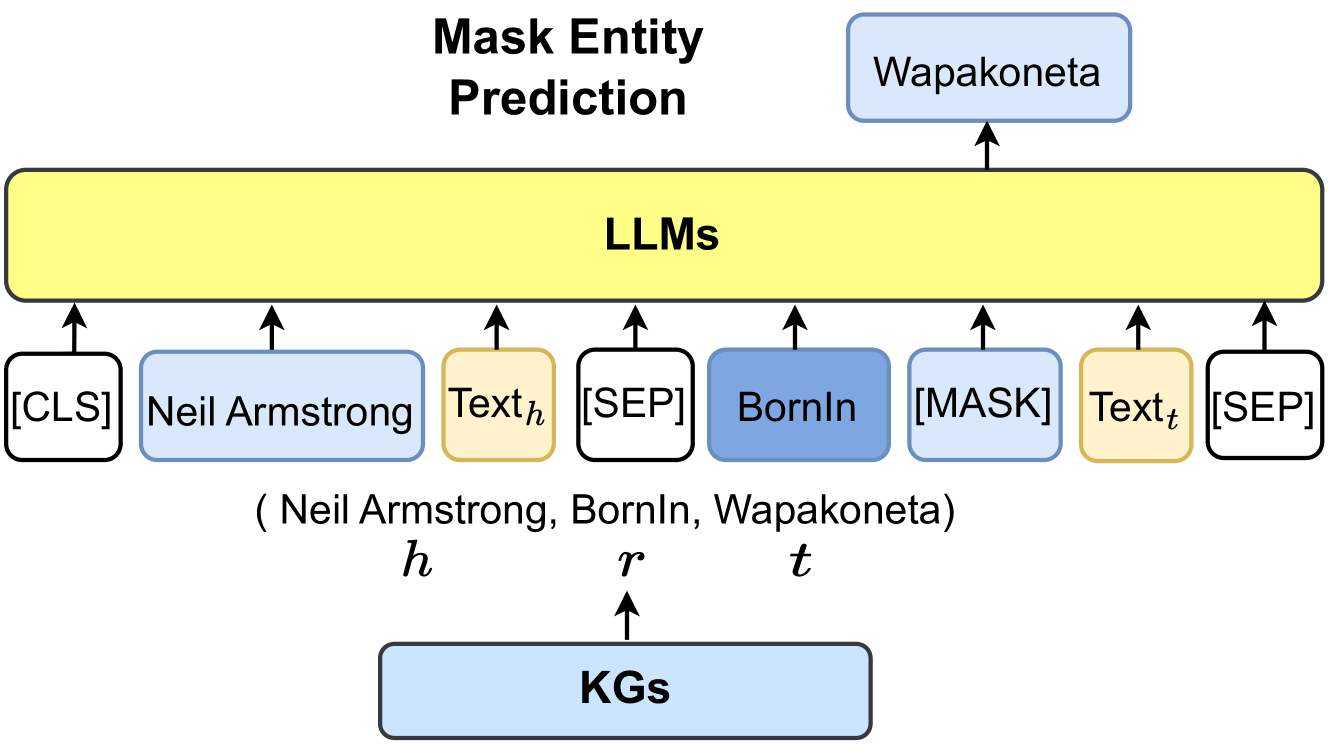
## Diagram: Mask Entity Prediction Process
### Overview
This image is a technical diagram illustrating a process called "Mask Entity Prediction." It depicts how a Large Language Model (LLM) is used to predict a missing entity (a masked token) within a structured knowledge triple, with the aid of Knowledge Graphs (KGs). The diagram uses a specific example involving Neil Armstrong to demonstrate the workflow.
### Components/Axes
The diagram is structured vertically with a clear top-to-bottom flow, segmented into three main regions:
1. **Header (Top Region):**
* **Title:** "Mask Entity Prediction" (centered, bold, black text).
* **Predicted Output:** A light blue, rounded rectangle containing the text "Wapakoneta" is positioned at the top-right. An upward-pointing arrow connects it to the main processing block below.
2. **Main Processing Block (Central Region):**
* **Core Processor:** A large, horizontal, yellow rectangle labeled "LLMs" (bold, black text). This represents the Large Language Model performing the prediction task.
* **Input Sequence:** A row of nine distinct tokens/elements below the "LLMs" block, each with an upward-pointing arrow indicating they are fed into the model. From left to right:
* A white, rounded rectangle: `[CLS]`
* A light blue, rounded rectangle: `Neil Armstrong`
* A yellow, rounded rectangle: `Textₕ`
* A white, rounded rectangle: `[SEP]`
* A medium blue, rounded rectangle: `BornIn`
* A light blue, rounded rectangle: `[MASK]`
* A yellow, rounded rectangle: `Textₜ`
* A white, rounded rectangle: `[SEP]`
* **Knowledge Triple Annotation:** Below the input sequence, the text `( Neil Armstrong, BornIn, Wapakoneta)` is written. Beneath this triple, the variables `h`, `r`, and `t` are placed directly under "Neil Armstrong," "BornIn," and "Wapakoneta," respectively, labeling them as head, relation, and tail.
3. **Footer (Bottom Region):**
* **Knowledge Source:** A light blue, rounded rectangle labeled "KGs" (bold, black text) is centered at the bottom.
* **Data Flow Arrow:** An upward-pointing arrow connects the "KGs" box to the variable `r` (the relation "BornIn") in the knowledge triple annotation above, indicating the source of the structured data.
### Detailed Analysis
The diagram explicitly models a **knowledge graph completion or entity prediction task** using a masked language modeling approach.
* **Input Structure:** The input to the LLM is a formatted sequence resembling a sentence with special tokens. It combines:
* **Special Tokens:** `[CLS]` (start of sequence) and `[SEP]` (separator) tokens, common in models like BERT.
* **Entity Head:** The known head entity "Neil Armstrong" (light blue).
* **Relation:** The known relation "BornIn" (medium blue).
* **Masked Tail:** The tail entity position is masked with `[MASK]` (light blue), which the model must predict.
* **Contextual Text:** Placeholders `Textₕ` and `Textₜ` (yellow) suggest additional textual context about the head and tail entities may be incorporated.
* **Process Flow:**
1. A knowledge triple `(Neil Armstrong, BornIn, ?)` is sourced from **KGs** (Knowledge Graphs).
2. The head (`h=Neil Armstrong`) and relation (`r=BornIn`) are encoded into the input sequence. The tail (`t`) is replaced with a `[MASK]` token.
3. This entire sequence is processed by the **LLMs** block.
4. The LLM outputs a prediction for the masked token, which is the entity "Wapakoneta."
* **Color Coding:**
* **Light Blue:** Used for entities (`Neil Armstrong`, `[MASK]`, `Wapakoneta`) and the `KGs` source.
* **Medium Blue:** Used specifically for the relation `BornIn`.
* **Yellow:** Used for the core `LLMs` processor and the contextual text placeholders (`Textₕ`, `Textₜ`).
* **White:** Used for structural special tokens (`[CLS]`, `[SEP]`).
### Key Observations
1. **Task Specificity:** The diagram is not a general model architecture but a specific instance of a **masked entity prediction task**.
2. **Hybrid Input:** The model integrates both **structured knowledge** (the triple from KGs) and **unstructured text** (implied by `Textₕ` and `Textₜ`) as inputs.
3. **Clear Data Provenance:** The arrow from "KGs" to the relation `r` explicitly shows the origin of the structured fact being completed.
4. **Spatial Grounding:** The predicted output "Wapakoneta" is spatially linked directly to the "LLMs" block, emphasizing it is the model's direct output. The `[MASK]` token in the input sequence is the specific element being resolved.
### Interpretation
This diagram demonstrates a **Peircean investigative** process of **abductive reasoning** within AI. It shows how a system can infer the most plausible missing piece of information (the "tail" entity) given a known context (head and relation).
* **What it Suggests:** The data suggests that LLMs can be effectively leveraged not just for open-ended text generation, but for precise, structured knowledge tasks. By framing a knowledge graph completion problem as a masked language modeling problem, the model's vast pre-trained knowledge about the world can be directed to fill gaps in a formal knowledge base.
* **How Elements Relate:** The **KGs** provide the foundational, structured fact. The **LLMs** act as the reasoning engine that understands the semantic relationship between "Neil Armstrong" and "BornIn" and retrieves the correct completion ("Wapakoneta") from its parametric memory. The input sequence format is the crucial bridge that translates a symbolic knowledge query into a form the neural network can process.
* **Notable Anomalies/Patterns:** The inclusion of `Textₕ` and `Textₜ` is a notable pattern. It implies the process isn't relying solely on the entity names but may enrich them with descriptive text, potentially improving prediction accuracy for less common entities. The diagram presents an ideal, successful case where the model correctly predicts the factual answer. It does not illustrate handling of ambiguity, multiple possible answers, or incorrect predictions.