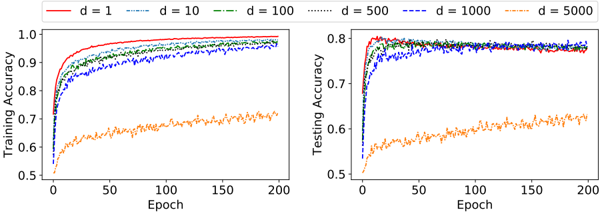
## Line Charts: Training and Testing Accuracy vs. Epoch for Different 'd' Values
### Overview
The image displays two side-by-side line charts comparing the performance of a model across different values of a parameter 'd' over 200 training epochs. The left chart shows **Training Accuracy**, and the right chart shows **Testing Accuracy**. Both charts share the same x-axis (Epoch) and a common legend.
### Components/Axes
* **Chart Type:** Two line charts, side-by-side.
* **X-Axis (Both Charts):** Labeled **"Epoch"**. The axis is linear, with major tick marks at 0, 50, 100, 150, and 200.
* **Y-Axis (Left Chart):** Labeled **"Training Accuracy"**. The scale is linear, ranging from 0.5 to 1.0, with major ticks at 0.5, 0.6, 0.7, 0.8, 0.9, and 1.0.
* **Y-Axis (Right Chart):** Labeled **"Testing Accuracy"**. The scale is linear, ranging from 0.5 to 0.8, with major ticks at 0.5, 0.6, 0.7, and 0.8.
* **Legend:** Positioned at the top, centered above both charts. It defines six data series corresponding to different values of 'd':
* `d = 1`: Solid red line.
* `d = 10`: Dashed blue line.
* `d = 100`: Dash-dot green line.
* `d = 500`: Dotted black line.
* `d = 1000`: Dashed dark blue line.
* `d = 5000`: Dash-dot orange line.
### Detailed Analysis
**Left Chart: Training Accuracy**
* **Trend Verification:** All lines show an upward trend, indicating learning. The rate of increase and final plateau value differ significantly by 'd'.
* **Data Series Analysis (Approximate Values):**
* **d=1 (Red):** Rises most rapidly. Reaches ~0.9 accuracy by epoch ~10. Plateaus near 1.0 (≈0.99) from epoch ~50 onward.
* **d=10 (Blue Dashed):** Rises quickly but slightly slower than d=1. Reaches ~0.95 by epoch ~25. Plateaus near ~0.98.
* **d=100 (Green Dash-Dot):** Follows a path very close to d=10, plateauing near ~0.98.
* **d=500 (Black Dotted):** Rises slower than the previous three. Reaches ~0.9 by epoch ~50. Plateaus near ~0.97.
* **d=1000 (Dark Blue Dashed):** Shows a slower, noisier ascent. Reaches ~0.85 by epoch ~50. Plateaus with high variance between ~0.92 and ~0.96.
* **d=5000 (Orange Dash-Dot):** Rises the slowest and shows the most noise. Starts near 0.5. Reaches ~0.6 by epoch ~25, ~0.65 by epoch ~100, and ends near ~0.7 at epoch 200. It remains far below all other curves.
**Right Chart: Testing Accuracy**
* **Trend Verification:** All lines show an initial sharp rise followed by a plateau. The final plateau values are lower than their training counterparts, indicating a generalization gap.
* **Data Series Analysis (Approximate Values):**
* **d=1 (Red):** Rises sharply to ~0.8 by epoch ~10. Plateaus with minor fluctuations around 0.79-0.80.
* **d=10 (Blue Dashed):** Rises quickly to ~0.78 by epoch ~20. Plateaus with noise between ~0.77 and ~0.79.
* **d=100 (Green Dash-Dot):** Very similar trajectory to d=10, plateauing in the ~0.77-0.79 range.
* **d=500 (Black Dotted):** Rises to ~0.77 by epoch ~30. Plateaus with noise between ~0.76 and ~0.78.
* **d=1000 (Dark Blue Dashed):** Rises to ~0.75 by epoch ~40. Plateaus with significant noise between ~0.74 and ~0.77.
* **d=5000 (Orange Dash-Dot):** Rises slowly and noisily. Reaches ~0.55 by epoch ~25, ~0.6 by epoch ~100, and ends near ~0.62 at epoch 200. It is the lowest-performing curve by a large margin.
### Key Observations
1. **Performance Hierarchy:** There is a clear inverse relationship between the parameter 'd' and model performance. Lower 'd' values (1, 10, 100) achieve higher final accuracy on both training and testing sets. `d=1` is the best performer.
2. **Convergence Speed:** Lower 'd' values lead to much faster convergence. `d=1` reaches near-peak performance within the first 10-20 epochs, while `d=5000` is still slowly climbing at epoch 200.
3. **Generalization Gap:** For all 'd' values, testing accuracy is lower than training accuracy. The gap is smallest for `d=1` (≈0.99 train vs. ≈0.80 test) and appears largest for `d=5000` (≈0.70 train vs. ≈0.62 test).
4. **Noise/Variance:** The curves for higher 'd' values (`d=1000`, `d=5000`) exhibit significantly more noise (jaggedness) during training and testing, suggesting less stable optimization.
5. **Clustering:** The performance of `d=10`, `d=100`, and `d=500` is relatively clustered, especially in testing accuracy, while `d=1` and `d=5000` are clear outliers on the high and low ends, respectively.
### Interpretation
This visualization demonstrates the critical impact of the hyperparameter 'd' on a model's learning dynamics and final performance. The data suggests that **'d' likely represents a parameter controlling model complexity, capacity, or regularization strength.**
* **Low 'd' (e.g., d=1):** Corresponds to a model that learns quickly and achieves high accuracy. The small generalization gap suggests it generalizes well, possibly indicating an optimal level of complexity for this task.
* **High 'd' (e.g., d=5000):** Corresponds to a model that learns very slowly, achieves poor final accuracy, and exhibits high training variance. This pattern is characteristic of **underfitting** or an optimization problem where the model is too constrained or the learning process is hindered. The large gap between its training and testing performance (both low) reinforces that the model is failing to capture the underlying data patterns effectively.
* **Practical Implication:** The charts provide a clear empirical basis for selecting a lower 'd' value (around 1-100) for this specific task to maximize accuracy and training efficiency. The value `d=5000` is demonstrably detrimental. The investigation would next focus on understanding the exact meaning of 'd' to explain why such a strong inverse relationship exists.