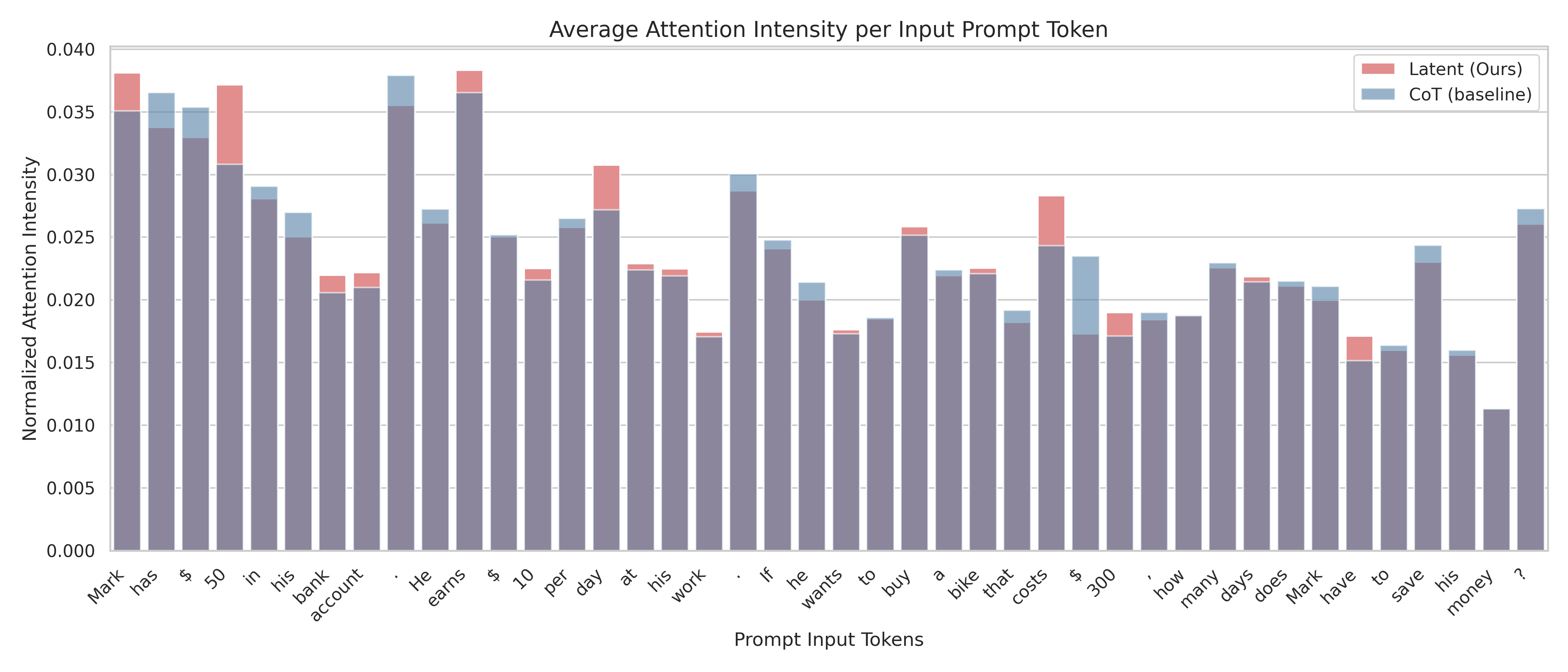
## Bar Chart: Average Attention Intensity per Input Prompt Token
### Overview
The chart compares normalized attention intensity across two models (Latent/Ours and CoT/baseline) for various prompt input tokens. Bars are segmented by model, with red representing Latent and blue representing CoT. The y-axis ranges from 0.000 to 0.040, while the x-axis lists 30+ prompt tokens (e.g., "Mark," "has," "$," "50," "in," "his," etc.).
### Components/Axes
- **X-axis (Prompt Input Tokens)**: 30+ tokens including nouns, verbs, symbols, and numbers (e.g., "Mark," "has," "$," "50," "in," "his," "bank," "account," "earns," "wants," "to," "buy," "save," "money," "?").
- **Y-axis (Normalized Attention Intensity)**: Scale from 0.000 to 0.040 in increments of 0.005.
- **Legend**: Top-right corner, with red = Latent (Ours), blue = CoT (baseline).
- **Bar Segmentation**: Each token’s bar is split vertically into red (Latent) and blue (CoT) segments.
### Detailed Analysis
- **Key Tokens with High Attention**:
- **Latent (red)**: "Mark" (~0.035), "earns" (~0.037), "day" (~0.030), "costs" (~0.028), "buy" (~0.025).
- **CoT (blue)**: "$" (~0.036), "50" (~0.035), "in" (~0.029), "his" (~0.027), "bank" (~0.026).
- **Low Attention**:
- **Latent**: "money" (~0.012), "?" (~0.010), "have" (~0.015).
- **CoT**: "money" (~0.013), "?" (~0.011), "have" (~0.016).
- **Trends**:
- Latent model shows higher attention for action-oriented tokens (e.g., "earns," "buy," "costs").
- CoT baseline exhibits broader attention across numerical/symbolic tokens (e.g., "$," "50," "300").
- Both models show reduced attention for abstract tokens like "money" and "?".
### Key Observations
1. **Latent Model Focus**: Prioritizes entities and actions (e.g., "Mark," "earns," "buy"), suggesting stronger entity recognition.
2. **CoT Baseline Spread**: More uniform attention across tokens, possibly reflecting a general-purpose processing strategy.
3. **Anomalies**:
- "money" and "?" tokens have significantly lower attention in both models.
- "save" shows higher CoT attention (~0.020) vs. Latent (~0.018), indicating task-specific differences.
### Interpretation
The data suggests the Latent model emphasizes critical entities and actions, potentially improving task efficiency. The CoT baseline’s broader attention may reflect a more generalized approach, useful for diverse contexts. The reduced attention to "money" and "?" could indicate limitations in handling abstract concepts or open-ended queries. These differences highlight trade-offs between specialized and general-purpose models in NLP tasks.