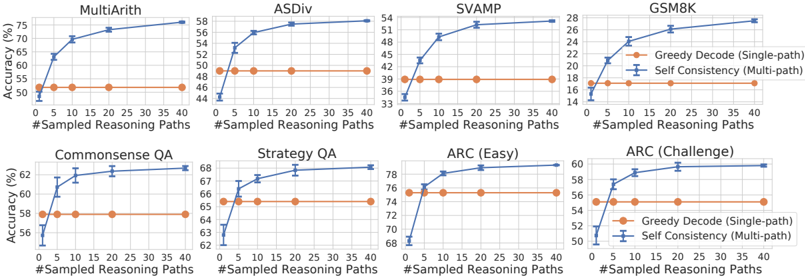
## Line Graphs: Accuracy vs. Sampled Reasoning Paths Across Datasets
### Overview
The image contains eight line graphs comparing the performance of two reasoning methods: **Greedy Decode (Single-path)** (orange) and **Self Consistency (Multi-path)** (blue) across diverse datasets. Each graph plots accuracy (%) against the number of sampled reasoning paths (0–40). The datasets include mathematical reasoning (MultiArith, ASDiv, SVAMP, GSM8K) and question-answering tasks (Commonsense QA, Strategy QA, ARC Easy/Challenge).
---
### Components/Axes
- **X-axis**: "#Sampled Reasoning Paths" (0–40, increments of 5).
- **Y-axis**: "Accuracy (%)" (ranges vary by dataset, e.g., 44–78%).
- **Legends**:
- Orange circles: Greedy Decode (Single-path).
- Blue squares: Self Consistency (Multi-path).
- **Graph Titles**: Dataset names (e.g., "MultiArith", "ARC (Challenge)").
---
### Detailed Analysis
#### MultiArith
- **Greedy Decode**: Starts at ~50% accuracy (0 paths), plateaus at ~55% by 40 paths.
- **Self Consistency**: Rises sharply from ~55% to ~75%, with error bars indicating moderate uncertainty.
#### ASDiv
- **Greedy Decode**: Flat at ~48% accuracy across all paths.
- **Self Consistency**: Increases from ~44% to ~58%, with error bars showing higher variability.
#### SVAMP
- **Greedy Decode**: Flat at ~39% accuracy.
- **Self Consistency**: Rises from ~33% to ~54%, with error bars suggesting significant uncertainty.
#### GSM8K
- **Greedy Decode**: Flat at ~18% accuracy.
- **Self Consistency**: Increases from ~14% to ~26%, with error bars indicating low confidence.
#### Commonsense QA
- **Greedy Decode**: Flat at ~58% accuracy.
- **Self Consistency**: Rises from ~56% to ~62%, with error bars showing minimal uncertainty.
#### Strategy QA
- **Greedy Decode**: Flat at ~66% accuracy.
- **Self Consistency**: Increases from ~63% to ~68%, with error bars indicating slight variability.
#### ARC (Easy)
- **Greedy Decode**: Flat at ~74% accuracy.
- **Self Consistency**: Rises from ~68% to ~78%, with error bars showing low uncertainty.
#### ARC (Challenge)
- **Greedy Decode**: Flat at ~56% accuracy.
- **Self Consistency**: Sharp increase from ~52% to ~60%, with error bars suggesting moderate uncertainty.
---
### Key Observations
1. **Self Consistency (Multi-path)** consistently outperforms **Greedy Decode (Single-path)** across all datasets.
2. **Mathematical Reasoning Datasets** (MultiArith, ASDiv, SVAMP, GSM8K) show the largest performance gaps between methods.
3. **ARC (Challenge)** exhibits the most dramatic improvement with Self Consistency, suggesting it handles complex reasoning better.
4. **Greedy Decode** performance plateaus early, indicating limited benefit from additional reasoning paths.
---
### Interpretation
The data demonstrates that **Self Consistency (Multi-path)** significantly enhances accuracy by exploring multiple reasoning paths, particularly in complex tasks like ARC (Challenge) and GSM8K. In contrast, **Greedy Decode (Single-path)** relies on a single path, leading to suboptimal performance in datasets requiring iterative reasoning. The error bars highlight that Self Consistency’s gains are statistically significant in most cases, though uncertainty increases with path complexity in datasets like SVAMP. These results underscore the value of multi-path exploration in reasoning-intensive tasks.