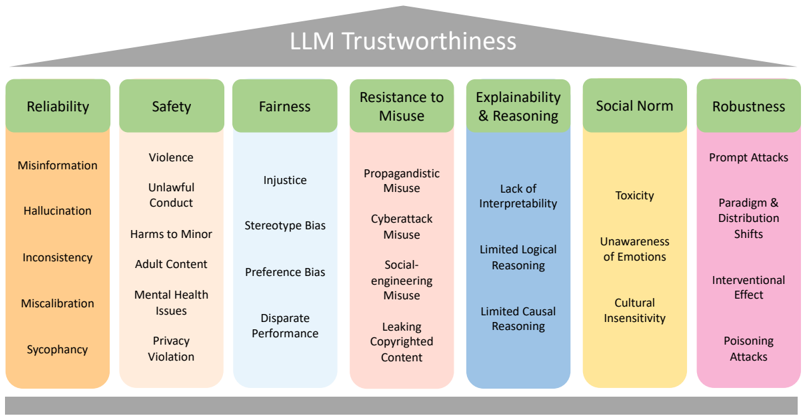
## Diagram: LLM Trustworthiness
### Overview
The diagram illustrates the key dimensions of trustworthiness in Large Language Models (LLMs), organized into seven categories. Each category is represented by a colored box with subcategories listed below, highlighting specific challenges or risks associated with LLM deployment.
### Components/Axes
- **Title**: "LLM Trustworthiness" (top center, gray header).
- **Legend**: Seven categories with distinct colors (orange, light orange, light blue, pink, blue, yellow, pink) positioned at the top.
- **Categories** (horizontal axis, left to right):
1. **Reliability** (orange)
2. **Safety** (light orange)
3. **Fairness** (light blue)
4. **Resistance to Misuse** (pink)
5. **Explainability & Reasoning** (blue)
6. **Social Norm** (yellow)
7. **Robustness** (pink)
### Detailed Analysis
#### Categories and Subcategories
1. **Reliability** (orange):
- Misinformation
- Hallucination
- Inconsistency
- Miscalibration
- Sycophancy
2. **Safety** (light orange):
- Violence
- Unlawful Conduct
- Harms to Minor
- Adult Content
- Mental Health Issues
- Privacy Violation
3. **Fairness** (light blue):
- Injustice
- Stereotype Bias
- Preference Bias
- Disparate Performance
4. **Resistance to Misuse** (pink):
- Propagandistic Misuse
- Cyberattack Misuse
- Social-engineering Misuse
- Leaking Copyrighted Content
5. **Explainability & Reasoning** (blue):
- Lack of Interpretability
- Limited Logical Reasoning
- Limited Causal Reasoning
6. **Social Norm** (yellow):
- Toxicity
- Unawareness of Emotions
- Cultural Insensitivity
7. **Robustness** (pink):
- Prompt Attacks
- Paradigm & Distribution Shifts
- Interventional Effect
- Poisoning Attacks
### Key Observations
- **Color Repetition**: "Resistance to Misuse" and "Robustness" share the same pink color, potentially causing ambiguity in visual distinction.
- **Subcategory Density**: "Safety" and "Resistance to Misuse" have the most subcategories (6 and 4, respectively), indicating higher complexity in these areas.
- **Categorical Focus**: All subcategories represent negative attributes or risks, emphasizing areas for improvement in LLM design.
### Interpretation
The diagram underscores the multifaceted nature of trustworthiness in LLMs, highlighting critical challenges across technical, ethical, and societal domains. For example:
- **Reliability** and **Safety** address foundational issues like accuracy and harm prevention.
- **Fairness** and **Social Norm** focus on equity and cultural sensitivity.
- **Resistance to Misuse** and **Robustness** emphasize security against adversarial attacks.
- **Explainability & Reasoning** points to transparency and logical coherence gaps.
The repetition of pink for "Resistance to Misuse" and "Robustness" may reflect a thematic link between security and resilience, though distinct subcategories suggest they should be visually differentiated. This framework provides a roadmap for prioritizing research and development efforts to enhance LLM trustworthiness.