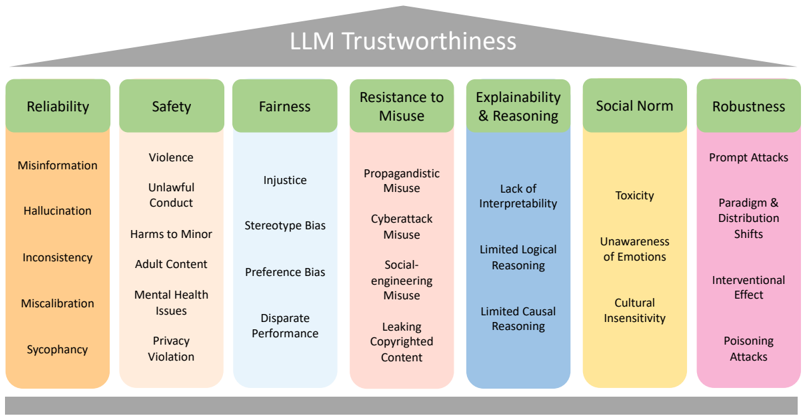
\n
## Diagram: LLM Trustworthiness Framework
### Overview
The image presents a diagram outlining the key dimensions of LLM (Large Language Model) trustworthiness. It's structured as a series of seven interconnected categories, each representing a crucial aspect of ensuring responsible and reliable LLM behavior. Each category is further broken down into specific concerns or risks. The diagram is visually organized with a header indicating the overall theme and rectangular blocks representing each dimension and its sub-categories.
### Components/Axes
The diagram consists of the following main components:
* **Header:** "LLM Trustworthiness" – positioned at the top center, visually represented as a gray curved shape.
* **Main Body:** Seven rectangular blocks arranged horizontally, each representing a dimension of trustworthiness. These are:
1. Reliability (Light Blue)
2. Safety (Orange)
3. Fairness (Green)
4. Resistance to Misuse (Pink)
5. Explainability & Reasoning (Blue)
6. Social Norm (Yellow)
7. Robustness (Teal)
* **Sub-categories:** Each rectangular block contains a list of specific concerns or risks associated with that dimension.
### Detailed Analysis or Content Details
Here's a breakdown of each dimension and its associated sub-categories:
1. **Reliability (Light Blue):**
* Misinformation
* Hallucination
* Inconsistency
* Miscalibration
* Sycophancy
2. **Safety (Orange):**
* Violence
* Unlawful Conduct
* Harms to Minor
* Adult Content
* Mental Health Issues
* Privacy Violation
3. **Fairness (Green):**
* Injustice
* Stereotype Bias
* Preference Bias
* Disparate Performance
4. **Resistance to Misuse (Pink):**
* Propagandistic Misuse
* Cyberattack Misuse
* Social-engineering Misuse
* Leaking Copyrighted Content
5. **Explainability & Reasoning (Blue):**
* Lack of Interpretability
* Limited Logical Reasoning
* Limited Causal Reasoning
6. **Social Norm (Yellow):**
* Toxicity
* Unawareness of Emotions
* Cultural Insensitivity
7. **Robustness (Teal):**
* Prompt Attacks
* Paradigm & Distribution Shifts
* Interventional Effect
* Poisoning Attacks
### Key Observations
The diagram highlights a comprehensive set of concerns related to LLM trustworthiness. The categorization suggests that trustworthiness isn't a single property but a multifaceted concept. The sub-categories within each dimension reveal specific areas where LLMs might fail to meet expectations of responsible behavior. The diagram does not contain any numerical data or trends. It is a qualitative framework.
### Interpretation
This diagram serves as a conceptual framework for evaluating and improving the trustworthiness of LLMs. It suggests that a holistic approach is needed, addressing issues related to reliability, safety, fairness, resistance to misuse, explainability, social norms, and robustness. The interconnectedness of these dimensions implies that addressing one area might have implications for others. For example, improving fairness might require addressing issues related to explainability and reasoning.
The diagram is useful for:
* **Identifying potential risks:** It provides a checklist of potential problems that developers and deployers of LLMs should consider.
* **Guiding research:** It highlights areas where further research is needed to develop techniques for mitigating these risks.
* **Facilitating discussion:** It provides a common language for discussing the ethical and societal implications of LLMs.
The absence of quantitative data suggests that this is a high-level conceptual model, rather than a data-driven analysis. It's a starting point for more detailed investigations into each of these dimensions. The diagram implicitly acknowledges the complexity of building trustworthy AI systems and the need for ongoing vigilance and improvement.