\n
## Scatter Plots: Accuracy vs. Max Thinking Length for Math Reasoning Benchmarks
### Overview
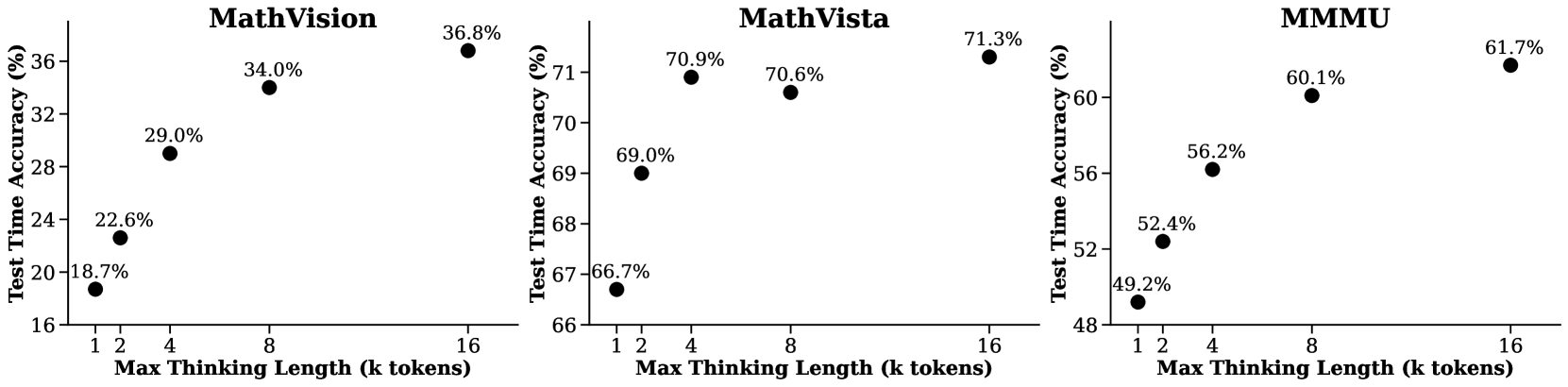
The image presents three separate scatter plots, each displaying the relationship between "Max Thinking Length (k tokens)" and "Test Time Accuracy (%)" for different math reasoning benchmarks: MathVision, MathVista, and MMMU. Each plot contains four data points, representing accuracy scores at different thinking lengths.
### Components/Axes
Each plot shares the following components:
* **X-axis:** "Max Thinking Length (k tokens)" with markers at 1, 2, 4, 8, and 16.
* **Y-axis:** "Test Time Accuracy (%)" ranging from approximately 16% to 72%.
* **Title:** Indicates the benchmark being evaluated (MathVision, MathVista, MMMU).
* **Data Points:** Black circular markers representing accuracy values at specific thinking lengths.
### Detailed Analysis
**1. MathVision**
* **Trend:** The accuracy generally increases as the Max Thinking Length increases.
* **Data Points:**
* Max Thinking Length = 1 k tokens: Accuracy ≈ 18.7%
* Max Thinking Length = 2 k tokens: Accuracy ≈ 22.6%
* Max Thinking Length = 4 k tokens: Accuracy ≈ 29.0%
* Max Thinking Length = 8 k tokens: Accuracy ≈ 34.0%
* Max Thinking Length = 16 k tokens: Accuracy ≈ 36.8%
**2. MathVista**
* **Trend:** The accuracy increases rapidly from 1 to 4 k tokens, then plateaus with a slight increase from 4 to 16 k tokens.
* **Data Points:**
* Max Thinking Length = 1 k tokens: Accuracy ≈ 66.7%
* Max Thinking Length = 2 k tokens: Accuracy ≈ 69.0%
* Max Thinking Length = 4 k tokens: Accuracy ≈ 70.9%
* Max Thinking Length = 8 k tokens: Accuracy ≈ 70.6%
* Max Thinking Length = 16 k tokens: Accuracy ≈ 71.3%
**3. MMMU**
* **Trend:** The accuracy increases steadily as the Max Thinking Length increases.
* **Data Points:**
* Max Thinking Length = 1 k tokens: Accuracy ≈ 49.2%
* Max Thinking Length = 2 k tokens: Accuracy ≈ 52.4%
* Max Thinking Length = 4 k tokens: Accuracy ≈ 56.2%
* Max Thinking Length = 8 k tokens: Accuracy ≈ 60.1%
* Max Thinking Length = 16 k tokens: Accuracy ≈ 61.7%
### Key Observations
* MathVista consistently achieves the highest accuracy across all thinking lengths.
* MathVision shows the lowest accuracy, but exhibits a clear positive correlation between thinking length and performance.
* The rate of accuracy improvement diminishes with increasing thinking length for MathVista, suggesting a point of diminishing returns.
* MMMU shows a consistent, linear improvement in accuracy with increasing thinking length.
### Interpretation
These plots demonstrate the impact of "Max Thinking Length" on the performance of language models on various math reasoning benchmarks. The "Max Thinking Length" parameter likely controls the amount of computational resources (tokens) allocated to the model for problem-solving.
The differences in accuracy across benchmarks suggest varying levels of complexity and the models' inherent capabilities in tackling different types of math problems. MathVista appears to be the easiest benchmark, as it achieves high accuracy even with limited thinking length. MathVision is the most challenging, requiring more extensive reasoning to achieve comparable results.
The diminishing returns observed in MathVista indicate that beyond a certain point, increasing the thinking length does not significantly improve performance. This could be due to the model reaching its capacity to effectively utilize additional computational resources for that specific task. The linear improvement in MMMU suggests that the model could potentially benefit from even longer thinking lengths, although practical limitations (computational cost) may exist.
These results are valuable for optimizing the performance of language models on math reasoning tasks by identifying the optimal balance between thinking length and accuracy for each benchmark.