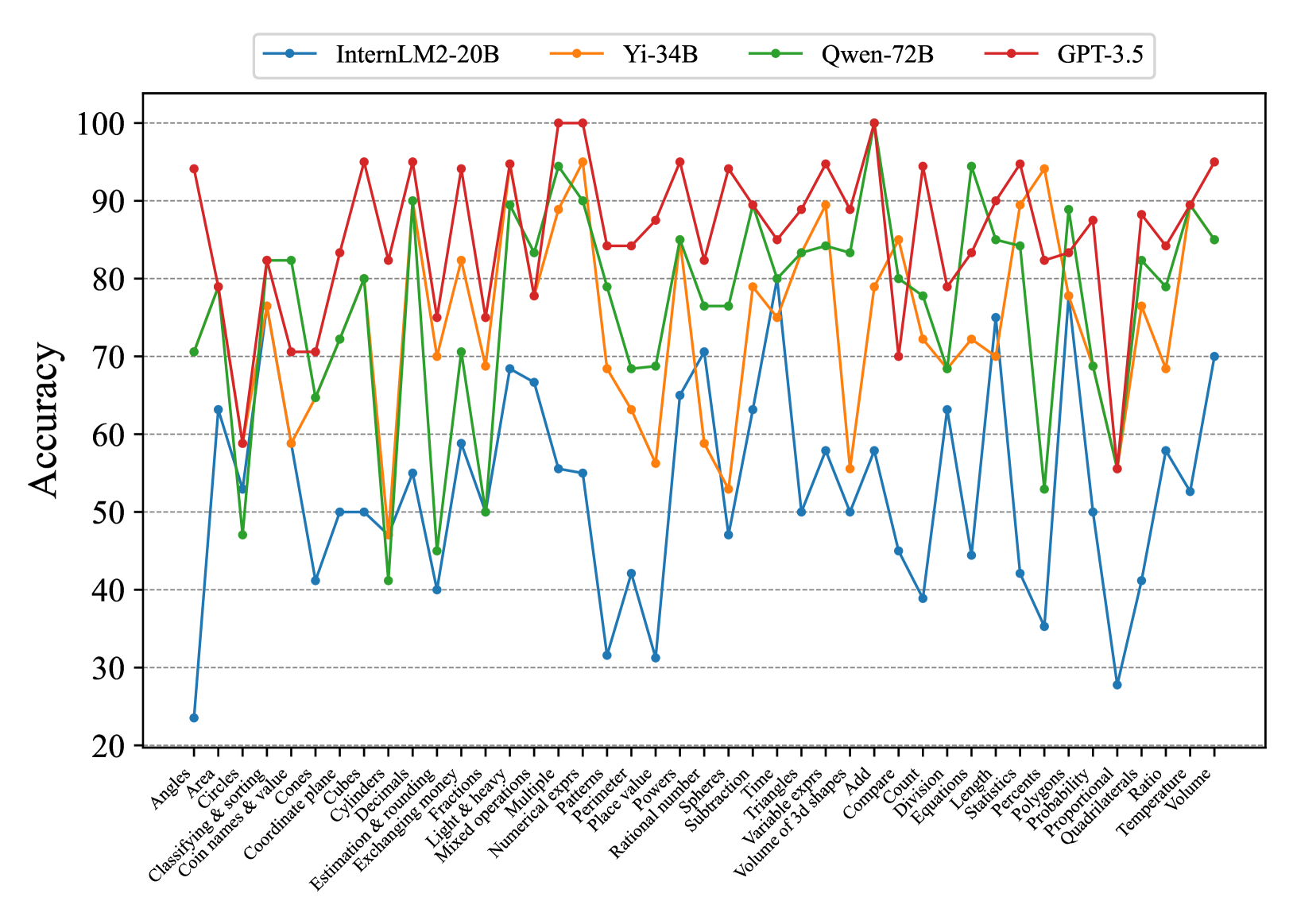
## Line Chart: Model Accuracy on Math Problems
### Overview
This line chart compares the accuracy of four large language models – InternLM2-20B, Yi-34B, Qwen-72B, and GPT-3.5 – on a series of math problems. The x-axis represents different math problem categories, and the y-axis represents the accuracy score, ranging from 20 to 100. The chart displays the performance of each model as a colored line across these categories.
### Components/Axes
* **X-axis Title:** Math Problem Categories (Angels, Area, Circles, Classifying & sorting, Coin names & value, Coordinate planes, Cubes, Decimals, Estimation & rounding, Exchanging, Fractions, Light & Heavy, Mixed operations, Numerical, Multiple, Patterns, Perimeter, Place value, Powers, Probability, Rational numbers, Spheres, Subtraction, Time, Triangles, Variable expressions, Volume of 3D shapes, Add, Compare, Division, Equations, Length, Polygons, Statistics, Proportional Ratio, Quadrilaterals, Temperature)
* **Y-axis Title:** Accuracy
* **Y-axis Scale:** 20 to 100, with increments of 10.
* **Legend:** Located at the top-center of the chart.
* InternLM2-20B (Blue Line)
* Yi-34B (Green Line)
* Qwen-72B (Light Green Line)
* GPT-3.5 (Red Line)
### Detailed Analysis
The chart presents accuracy scores for each model across 30 different math problem categories. Here's a breakdown of the trends and approximate data points, verifying color consistency with the legend:
* **InternLM2-20B (Blue):** Starts around 70 accuracy for "Angles", dips to approximately 40-50 for "Cubes", "Decimals", "Estimation & rounding", and "Fractions", then rises to around 80-90 for "Numerical", "Patterns", "Place value", and "Powers". It then declines again, ending around 30 for "Temperature". The line exhibits significant fluctuations.
* **Yi-34B (Green):** Begins at approximately 85 for "Angles", shows a dip to around 60-70 for "Cubes", "Decimals", and "Estimation & rounding", then rises to a peak of around 95-100 for "Numerical", "Patterns", "Place value", and "Powers". It then declines, ending around 80 for "Temperature". This line is generally higher than InternLM2-20B.
* **Qwen-72B (Light Green):** Starts around 60 for "Angles", dips to around 40-50 for "Cubes", "Decimals", "Estimation & rounding", and "Fractions", then rises to around 80-90 for "Numerical", "Patterns", "Place value", and "Powers". It then declines, ending around 60 for "Temperature". This line is similar to InternLM2-20B, but generally lower.
* **GPT-3.5 (Red):** Starts around 90 for "Angles", dips to around 70-80 for "Cubes", "Decimals", "Estimation & rounding", and "Fractions", then rises to a peak of around 95-100 for "Numerical", "Patterns", "Place value", and "Powers". It then declines, ending around 30 for "Temperature". This line is generally the highest performing, but experiences a significant drop-off towards the end.
Specific Data Points (approximate):
| Category | InternLM2-20B | Yi-34B | Qwen-72B | GPT-3.5 |
| -------------------- | ------------- | ------ | -------- | ------- |
| Angles | 70 | 85 | 60 | 90 |
| Cubes | 45 | 65 | 45 | 75 |
| Decimals | 50 | 60 | 50 | 70 |
| Estimation & rounding| 40 | 60 | 40 | 70 |
| Fractions | 50 | 70 | 50 | 80 |
| Numerical | 85 | 98 | 80 | 95 |
| Patterns | 90 | 100 | 90 | 98 |
| Place value | 80 | 95 | 80 | 95 |
| Powers | 85 | 98 | 85 | 95 |
| Temperature | 30 | 80 | 60 | 30 |
### Key Observations
* All models demonstrate higher accuracy in categories like "Numerical", "Patterns", "Place value", and "Powers".
* All models struggle with "Cubes", "Decimals", "Estimation & rounding", and "Fractions".
* GPT-3.5 generally outperforms the other models, especially in the initial categories, but experiences a significant drop in accuracy towards the end.
* Yi-34B consistently performs well, often rivaling or exceeding GPT-3.5 in certain categories.
* InternLM2-20B and Qwen-72B exhibit similar performance profiles, generally lower than Yi-34B and GPT-3.5.
### Interpretation
The data suggests that these large language models exhibit varying levels of proficiency in different mathematical domains. They excel at tasks involving numerical reasoning, pattern recognition, and place value, likely due to the abundance of such data in their training sets. However, they struggle with more complex concepts like cubes, decimals, estimation, and fractions, indicating a potential gap in their understanding of these areas.
The significant drop in accuracy for all models towards the end (e.g., "Temperature") could indicate that these problems require a different type of reasoning or knowledge base not well-represented in their training data. The performance differences between the models highlight the impact of model size and architecture on mathematical problem-solving abilities. GPT-3.5's initial strong performance, followed by a decline, might suggest overfitting to certain types of problems or a lack of generalization ability. Yi-34B's consistent performance suggests a more robust and well-rounded understanding of mathematical concepts. The chart provides valuable insights into the strengths and weaknesses of these models, which can inform future research and development efforts aimed at improving their mathematical reasoning capabilities.