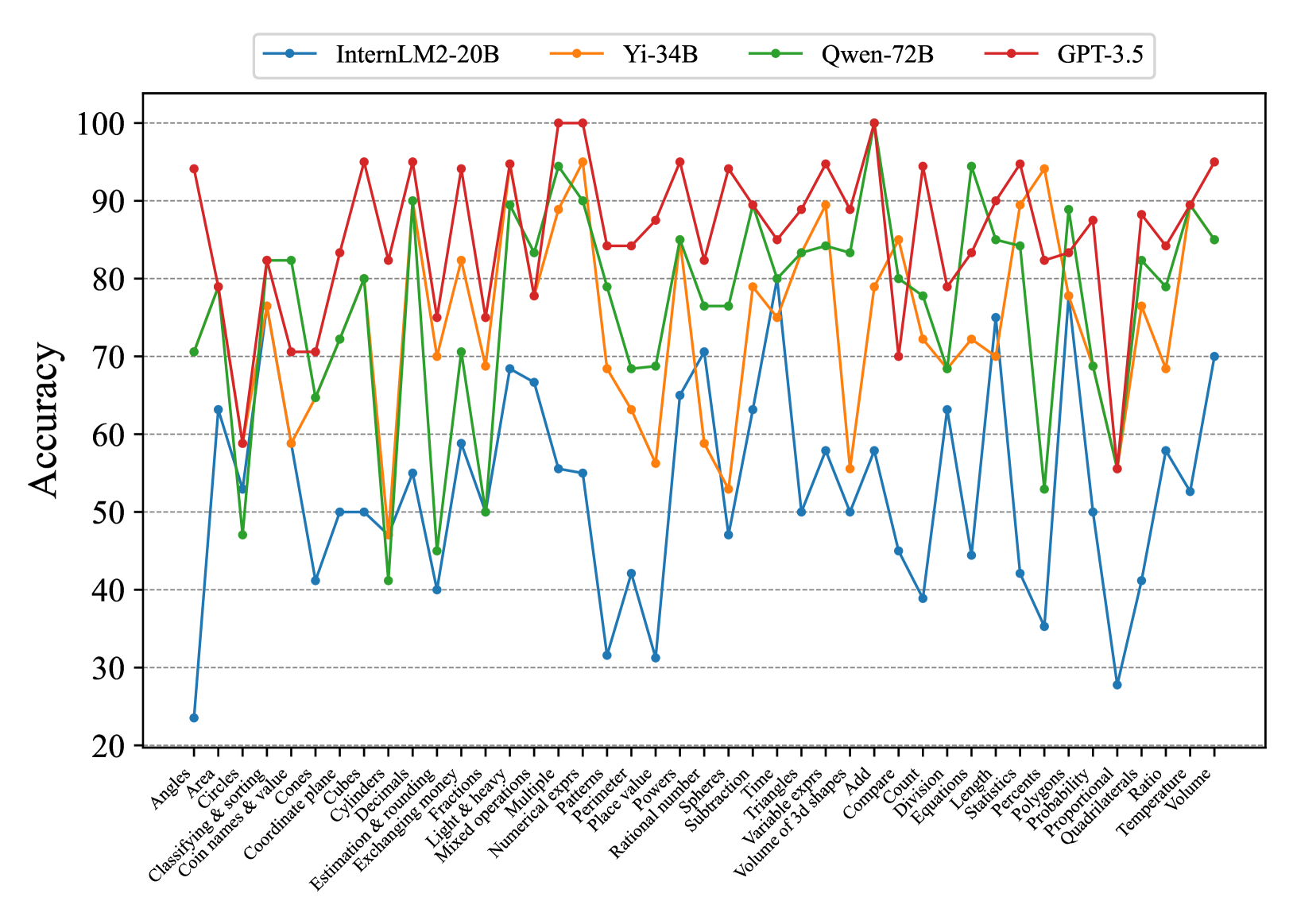
## Line Graph: Model Accuracy Across Tasks
### Overview
The image is a line graph comparing the accuracy of four AI models (InternLM2-20B, Yi-34B, Qwen-72B, GPT-3.5) across 30 distinct tasks. The x-axis lists tasks (e.g., "Angles," "Area," "Classifying & sorting"), while the y-axis represents accuracy as a percentage from 20 to 100. Four colored lines (blue, orange, green, red) correspond to the models, with the legend positioned at the top.
### Components/Axes
- **X-axis**: Task categories (e.g., "Angles," "Area," "Classifying & sorting," "Coordinate plane," "Cubes," "Cylinders," "Decimals," "Estimation & rounding," "Fractions," "Light & heavy," "Mixed operations," "Multiple expressions," "Numerical exprs," "Patterns," "Perimeter," "Place value," "Powers," "Rational number," "Spheres," "Subtraction," "Time," "Triangles," "Variable exprs," "Volume of 3d shapes," "Add," "Compare," "Count," "Division," "Equations," "Length," "Statistics," "Percentages," "Polygons," "Probability," "Proportional," "Proportional 3d shapes," "Ratio," "Temperature," "Volume").
- **Y-axis**: Accuracy (20–100, increments of 10).
- **Legend**:
- Blue: InternLM2-20B
- Orange: Yi-34B
- Green: Qwen-72B
- Red: GPT-3.5
### Detailed Analysis
- **GPT-3.5 (Red Line)**:
- Consistently the highest-performing model, with peaks reaching 100% in tasks like "Multiple expressions" and "Compare."
- Notable dips in "Angles" (~60%) and "Proportional 3d shapes" (~55%).
- Average accuracy: ~85–95% across most tasks.
- **Qwen-72B (Green Line)**:
- Strong performance in "Multiple expressions" (~95%) and "Compare" (~90%).
- Significant drops in "Angles" (~45%) and "Proportional 3d shapes" (~60%).
- Average accuracy: ~75–90%.
- **Yi-34B (Orange Line)**:
- Peaks at ~95% in "Multiple expressions" and "Compare."
- Low points in "Angles" (~50%) and "Proportional 3d shapes" (~65%).
- Average accuracy: ~70–85%.
- **InternLM2-20B (Blue Line)**:
- Lowest overall performance, with a sharp drop to ~25% in "Angles."
- Peaks at ~70% in "Multiple expressions" and "Compare."
- Average accuracy: ~40–70%.
### Key Observations
1. **GPT-3.5 Dominance**: The red line (GPT-3.5) consistently outperforms others, with the highest peaks and fewest dips.
2. **Task-Specific Variability**:
- "Angles" is the weakest task for all models, with InternLM2-20B (blue) at ~25% and GPT-3.5 (red) at ~60%.
- "Multiple expressions" and "Compare" are the strongest tasks, with all models achieving 80–100% accuracy.
3. **Model-Specific Trends**:
- **InternLM2-20B (Blue)**: Most erratic performance, with extreme lows (e.g., "Angles") and moderate highs.
- **Yi-34B (Orange)**: Moderate variability, with mid-range accuracy across most tasks.
- **Qwen-72B (Green)**: Strong in complex tasks but struggles with basic geometry ("Angles").
- **GPT-3.5 (Red)**: Most consistent, with minimal dips and high peaks.
### Interpretation
The data suggests that GPT-3.5 (red) is the most robust model, excelling in both complex and basic tasks. Qwen-72B (green) and Yi-34B (orange) show task-specific strengths but lag behind GPT-3.5 in consistency. InternLM2-20B (blue) underperforms significantly, particularly in foundational tasks like "Angles." The graph highlights the importance of model architecture and training data in handling diverse computational challenges. Outliers like the blue line's 25% accuracy in "Angles" indicate potential limitations in specific domains, while the red line's 100% peaks in "Multiple expressions" underscore its advanced capabilities in symbolic reasoning.