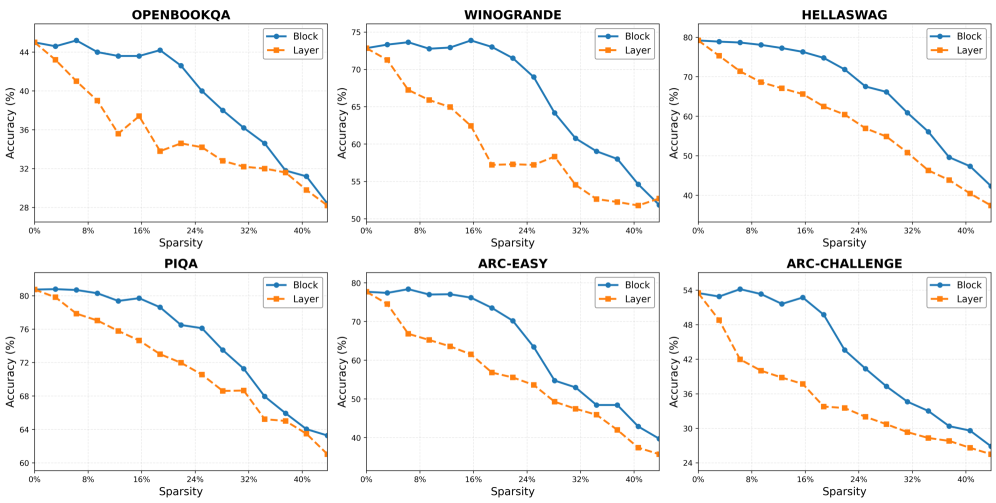
## Line Charts: Sparsity vs. Accuracy Across Six Benchmarks
### Overview
The image displays a 2x3 grid of six line charts. Each chart compares the performance (Accuracy %) of two model pruning methods—"Block" and "Layer"—across increasing levels of model sparsity (Sparsity %). The benchmarks evaluated are OPENBOOKQA, WINOGRANDE, HELLASWAG, PIQA, ARC-EASY, and ARC-CHALLENGE. The consistent visual pattern across all charts is that the "Block" method (blue solid line) maintains higher accuracy than the "Layer" method (orange dashed line) as sparsity increases.
### Components/Axes
* **Chart Titles (Top-Center of each subplot):** OPENBOOKQA, WINOGRANDE, HELLASWAG, PIQA, ARC-EASY, ARC-CHALLENGE.
* **X-Axis (All charts):** Label: "Sparsity (%)". Scale: 0% to 40%, with major tick marks at 0%, 8%, 16%, 24%, 32%, 40%.
* **Y-Axis (All charts):** Label: "Accuracy (%)". The scale range varies per benchmark to best display the data.
* **Legend (Top-Right of each subplot):**
* **Block:** Blue solid line with circular markers.
* **Layer:** Orange dashed line with square markers.
### Detailed Analysis
**1. OPENBOOKQA**
* **Trend:** Both lines show a general downward trend. The "Layer" line drops more steeply and erratically initially, while the "Block" line declines more gradually and smoothly.
* **Approximate Data Points:**
* **Block:** Starts ~45% (0% sparsity), peaks ~46% (~4% sparsity), then declines to ~28% (40% sparsity).
* **Layer:** Starts ~45% (0% sparsity), drops sharply to ~36% (~12% sparsity), recovers slightly to ~38% (~16% sparsity), then declines to ~28% (40% sparsity).
**2. WINOGRANDE**
* **Trend:** Both lines decline. The "Layer" line experiences a very sharp drop between 0% and 20% sparsity, then plateaus. The "Block" line maintains a high accuracy longer before a steep decline after 24% sparsity.
* **Approximate Data Points:**
* **Block:** Starts ~73% (0% sparsity), remains above 70% until ~20% sparsity, then falls to ~52% (40% sparsity).
* **Layer:** Starts ~73% (0% sparsity), plummets to ~57% (~20% sparsity), then gradually declines to ~52% (40% sparsity).
**3. HELLASWAG**
* **Trend:** A steady, near-linear decline for both methods. The "Block" line is consistently above the "Layer" line by a margin of approximately 5-10 percentage points across the sparsity range.
* **Approximate Data Points:**
* **Block:** Starts ~79% (0% sparsity), declines steadily to ~42% (40% sparsity).
* **Layer:** Starts ~76% (0% sparsity), declines steadily to ~37% (40% sparsity).
**4. PIQA**
* **Trend:** Both lines show a smooth, consistent downward slope. The gap between "Block" and "Layer" remains relatively constant.
* **Approximate Data Points:**
* **Block:** Starts ~81% (0% sparsity), declines to ~63% (40% sparsity).
* **Layer:** Starts ~81% (0% sparsity), declines to ~60% (40% sparsity).
**5. ARC-EASY**
* **Trend:** Similar to WINOGRANDE, the "Layer" line drops sharply early on. The "Block" line holds its accuracy better until around 20% sparsity before declining more rapidly.
* **Approximate Data Points:**
* **Block:** Starts ~78% (0% sparsity), stays near 78% until ~12% sparsity, then falls to ~40% (40% sparsity).
* **Layer:** Starts ~78% (0% sparsity), drops to ~62% (~16% sparsity), then declines to ~35% (40% sparsity).
**6. ARC-CHALLENGE**
* **Trend:** Both lines decline. The "Block" line shows more volatility (a small peak around 8% sparsity) but maintains a clear advantage. The "Layer" line declines more smoothly.
* **Approximate Data Points:**
* **Block:** Starts ~53% (0% sparsity), peaks ~54% (~8% sparsity), then declines to ~28% (40% sparsity).
* **Layer:** Starts ~53% (0% sparsity), declines steadily to ~25% (40% sparsity).
### Key Observations
1. **Universal Superiority of Block Sparsity:** In every benchmark and at nearly every sparsity level, the "Block" method yields higher accuracy than the "Layer" method.
2. **Differential Degradation:** The "Layer" method often suffers a more severe and immediate drop in accuracy with the introduction of sparsity (especially visible in WINOGRANDE and ARC-EASY), while the "Block" method tends to maintain baseline performance for a longer "grace period" before declining.
3. **Convergence at High Sparsity:** For several benchmarks (OPENBOOKQA, WINOGRANDE), the performance gap between the two methods narrows significantly at the highest measured sparsity (40%), suggesting a potential performance floor.
4. **Benchmark Sensitivity:** The absolute accuracy values and the shape of the degradation curves vary significantly across benchmarks, indicating that the impact of sparsity is highly dependent on the specific task.
### Interpretation
The data strongly suggests that **block-structured pruning ("Block") is a more robust and effective technique for model compression than layer-wise pruning ("Layer")** across a diverse set of language understanding benchmarks. The "Block" method's ability to preserve accuracy at lower sparsity levels implies it better maintains the functional integrity of the model's internal representations. The sharp early drop for "Layer" pruning indicates that removing individual weights indiscriminately within a layer disrupts critical pathways more severely than removing structured blocks. The convergence at high sparsity may indicate that both methods eventually remove so much of the model that task performance is fundamentally compromised, regardless of the pruning structure. This analysis provides empirical evidence for preferring structured (block) pruning over unstructured or layer-wise approaches when seeking to reduce model size while preserving performance on reasoning and knowledge tasks.