# Technical Document Extraction: Robotic Task Inference Interface
## 1. Image Overview
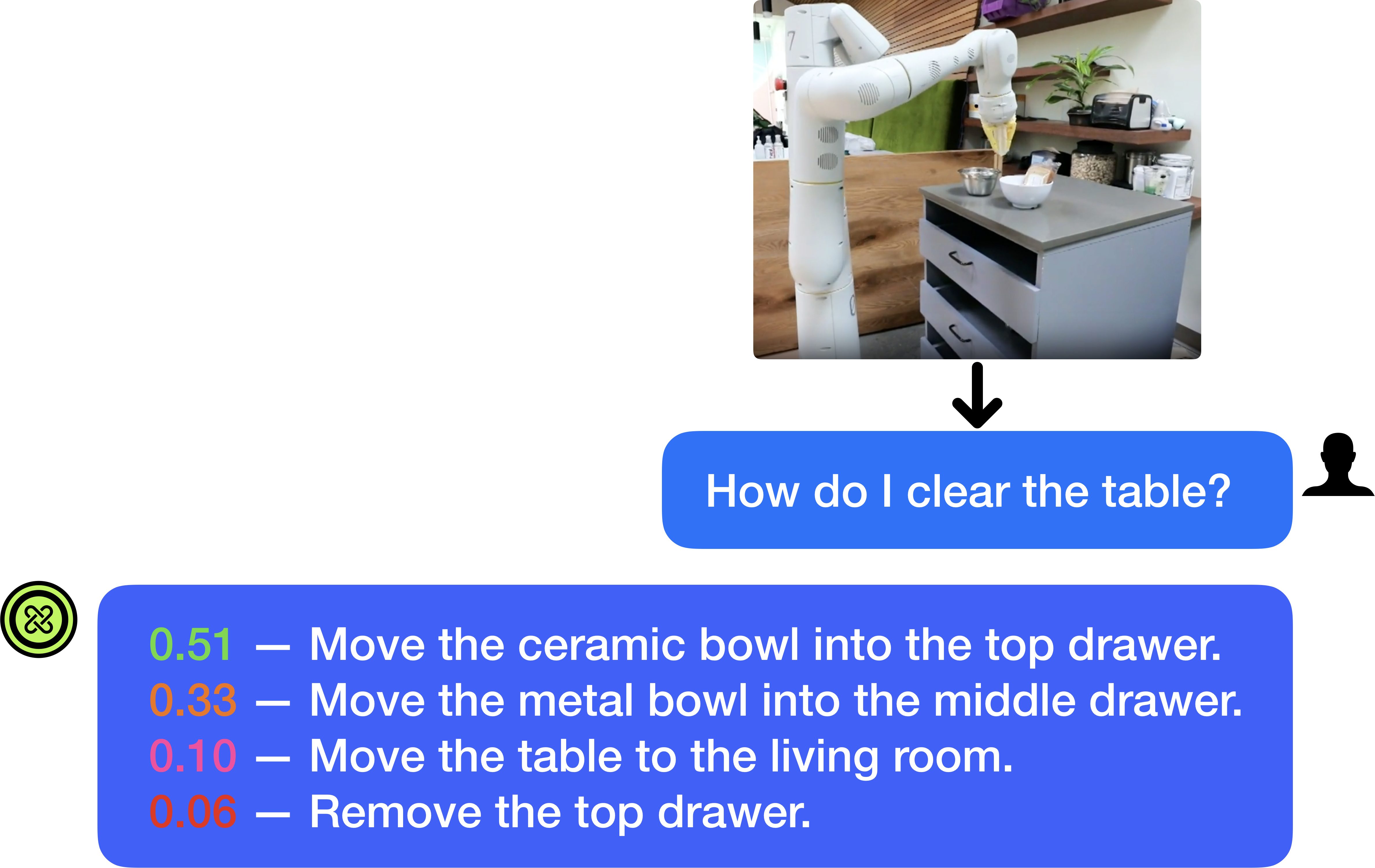
This image depicts a user interface (UI) flow for a multimodal AI system, likely a Large Language Model (LLM) integrated with robotics. The flow illustrates an image input, a natural language query, and a ranked list of predicted robotic actions with associated confidence scores.
---
## 2. Component Segmentation
### Region A: Visual Input (Top Right)
* **Type:** Photographic Image.
* **Content:** A white collaborative robot arm (cobot) positioned in a kitchen or office breakroom environment.
* **Scene Details:**
* The robot is positioned next to a grey cabinet with three drawers.
* On top of the cabinet are two bowls: one white ceramic bowl and one smaller metal bowl.
* The background includes wooden slat walls, shelving with containers (nuts/grains), and a potted plant.
* **Flow Indicator:** A black downward-pointing arrow connects this image to the user query.
### Region B: User Query (Middle Right)
* **Type:** Chat Bubble (Blue).
* **Icon:** A black silhouette of a person's head and shoulders is positioned to the right of the bubble.
* **Transcribed Text:** "How do I clear the table?"
### Region C: System Response (Bottom)
* **Type:** Chat Bubble (Blue).
* **Icon:** A green circular logo with a stylized "X" or knot pattern is positioned to the left of the bubble.
* **Content Type:** A list of four potential actions, each preceded by a numerical value (confidence score) and a dash.
---
## 3. Data Extraction: Action Predictions
The system provides a ranked list of actions. The numerical values represent probability or confidence scores (summing to 1.00).
| Confidence Score | Color Code | Action Description |
| :--- | :--- | :--- |
| **0.51** | Green | Move the ceramic bowl into the top drawer. |
| **0.33** | Orange | Move the metal bowl into the middle drawer. |
| **0.10** | Pink/Red | Move the table to the living room. |
| **0.06** | Red/Orange | Remove the top drawer. |
---
## 4. Trend and Logic Analysis
* **Primary Intent:** The system identifies "Move the ceramic bowl into the top drawer" as the most likely intended action (51% confidence).
* **Secondary Intent:** "Move the metal bowl into the middle drawer" is the second most likely (33% confidence).
* **Outlier/Low Confidence:** The system assigns very low probability to moving the entire table (10%) or removing the drawer itself (6%), suggesting these are interpreted as less logical responses to the command "clear the table" in this context.
* **Spatial Grounding:** The system correctly identifies objects in the image (ceramic bowl, metal bowl, top drawer, middle drawer) and maps them to the linguistic command.
---
## 5. Technical Summary
This document represents a **Multimodal Task Planning** interface. It demonstrates the translation of a high-level human instruction ("clear the table") into discrete, executable robotic sub-tasks based on visual context. The output format suggests a probabilistic model where multiple hypotheses are generated and ranked.