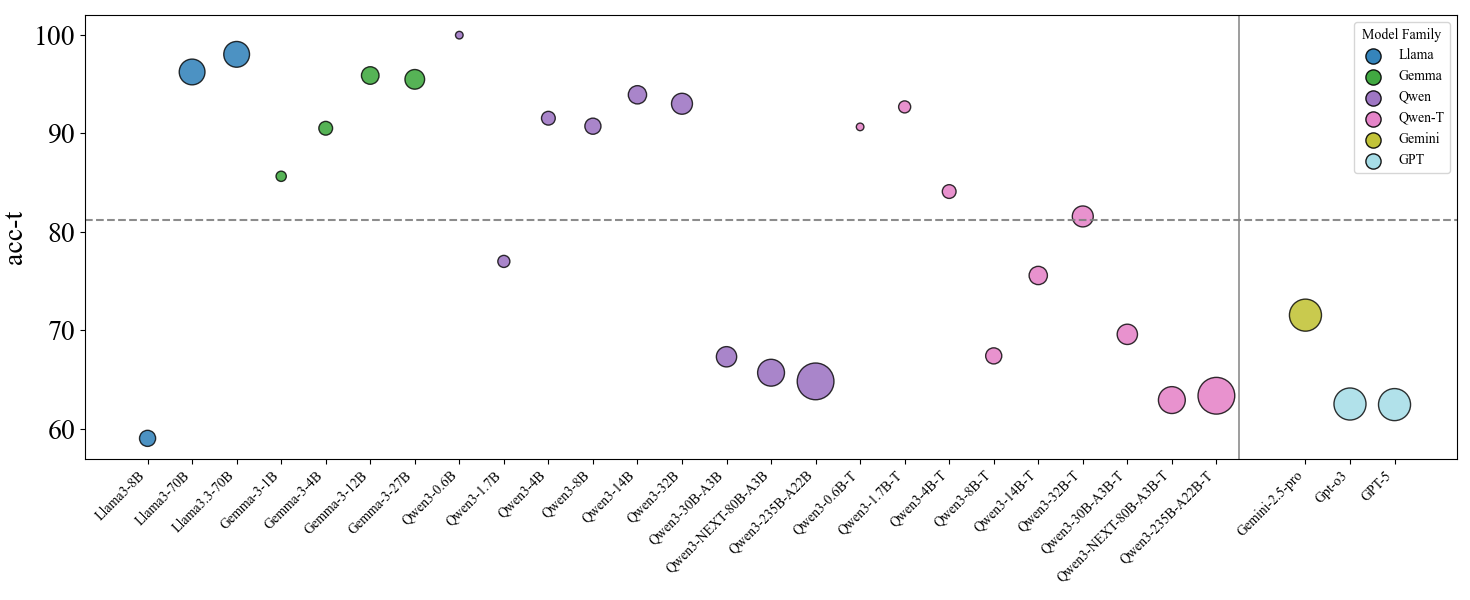
## Scatter Plot: Model Accuracy Comparison
### Overview
The image is a scatter plot comparing the accuracy (acc-t) of various large language models (LLMs) across different model families. The y-axis represents accuracy (60-100), while the x-axis lists specific model variants. Different colors represent distinct model families, with a legend on the right for reference.
### Components/Axes
- **Y-axis**: "acc-t" (accuracy metric), scaled from 60 to 100 in increments of 10.
- **X-axis**: Model names (e.g., "Llama3-8B", "Gemma3-27B", "GPT-5"), ordered left-to-right.
- **Legend**: Located in the top-right corner, mapping colors to model families:
- Blue: Llama
- Green: Gemma
- Purple: Gwen
- Pink: Gwen-T
- Yellow: Gemini
- Light Blue: GPT
### Detailed Analysis
1. **Llama Family** (Blue):
- Llama3-8B: 59
- Llama3-70B: 96
- Llama3-3-70B: 98
- Llama3-3-1B: 85
2. **Gemma Family** (Green):
- Gemma3-3-12B: 95
- Gemma3-3-27B: 96
- Gemma3-3-4B: 87
3. **Gwen Family** (Purple):
- Gwen3-3-0.6B: 100
- Gwen3-3-1.7B: 77
- Gwen3-3-4B: 92
- Gwen3-3-8B: 93
- Gwen3-3-14B: 94
- Gwen3-3-32B: 67
- Gwen3-3-30B-A3B: 68
- Gwen3-3-NEXT-80B-A3B: 66
- Gwen3-3-235B-A22B: 65
4. **Gwen-T Family** (Pink):
- Gwen3-3-0.6B-T: 91
- Gwen3-3-8B-T: 84
- Gwen3-3-14B-T: 77
- Gwen3-3-32B-T: 81
- Gwen3-3-30B-A3B-T: 70
- Gwen3-3-NEXT-80B-A3B-T: 64
- Gwen3-3-235B-A22B-T: 63
- Gwen3-3-235B-A22B-T: 65
5. **Gemini Family** (Yellow):
- Gemini-2.5-pro: 71
6. **GPT Family** (Light Blue):
- GPT-3: 63
- GPT-5: 63
### Key Observations
- **Highest Accuracy**: Gwen3-3-0.6B (100) and Llama3-3-70B (98) achieve near-perfect scores.
- **Lowest Accuracy**: Llama3-8B (59) and GPT-3/GPT-5 (63) perform significantly below the 80% threshold.
- **Model Size Correlation**: Larger models (e.g., 70B, 235B) generally show higher accuracy, but exceptions exist (e.g., GPT-5 at 63).
- **Threshold Line**: The dashed line at 80% separates high-performing models (above) from lower-performing ones (below).
- **Outliers**: Gemini-2.5-pro (71) underperforms relative to its size compared to other families.
### Interpretation
The data suggests a strong correlation between model size and accuracy, with larger models (e.g., 70B, 235B) typically achieving higher scores. However, this trend is not universal—GPT-5 and Gemini-2.5-pro underperform relative to their size. The Gwen3-3-0.6B model stands out as an anomaly with perfect accuracy despite its smaller size. The dashed 80% threshold acts as a benchmark, highlighting models that meet or exceed this standard. The Gwen-T family shows a notable drop in accuracy when transitioning to larger variants (e.g., Gwen3-3-235B-A22B-T at 65 vs. Gwen3-3-0.6B-T at 91), suggesting potential architectural or training challenges in scaling. The plot underscores the importance of model architecture and training methodology beyond mere parameter count in determining performance.