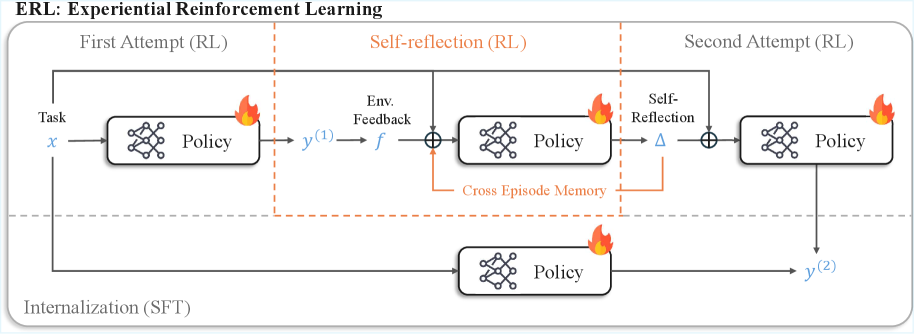
## Diagram: ERL (Experiential Reinforcement Learning) Process Flow
### Overview
The diagram illustrates a cyclical process of Experiential Reinforcement Learning (ERL) with three primary phases: First Attempt (RL), Self-reflection (RL), and Second Attempt (RL). It emphasizes iterative policy improvement through environmental feedback, cross-episode memory, and internalization. Key components include task input, policy networks, feedback loops, and memory mechanisms.
### Components/Axes
- **Title**: "ERL: Experiential Reinforcement Learning"
- **Sections**:
1. **First Attempt (RL)**:
- Input: Task (`x`)
- Output: Policy → `y^(1)`
- Feedback: Environment Feedback (`f`) → Policy
2. **Self-reflection (RL)**:
- Cross-Episode Memory (bidirectional arrow between First and Second Attempts)
- Self-Reflection (triangle symbol) → Policy
3. **Second Attempt (RL)**:
- Output: Policy → `y^(2)`
4. **Internalization (SFT)**:
- Direct input to Policy (dashed line)
- **Visual Elements**:
- Flame icons (🔥) on Policy components (red/orange color)
- Dashed lines for internalization and cross-episode memory
- Orange dashed box highlighting the Self-reflection section
### Detailed Analysis
- **First Attempt (RL)**:
- Task (`x`) → Policy (flame icon) → `y^(1)`
- Environment Feedback (`f`) loops back to Policy, suggesting iterative adjustment.
- **Self-reflection (RL)**:
- Cross-Episode Memory connects `y^(1)` (First Attempt) and `y^(2)` (Second Attempt), enabling knowledge transfer.
- Self-Reflection (triangle) feeds into Policy, indicating meta-cognitive processing.
- **Second Attempt (RL)**:
- Policy → `y^(2)`, showing improved output after reflection.
- **Internalization (SFT)**:
- Dashed line from Internalization to Policy suggests a foundational learning phase (e.g., self-supervised fine-tuning).
### Key Observations
1. **Iterative Improvement**: The flow from `y^(1)` to `y^(2)` demonstrates incremental policy refinement.
2. **Memory Integration**: Cross-Episode Memory bridges attempts, preventing knowledge silos.
3. **Self-Reflection Role**: The triangle symbol acts as a decision node, likely evaluating past actions.
4. **Internalization**: Positioned separately, it may represent a pre-training or foundational learning stage.
### Interpretation
The diagram models ERL as a closed-loop system where policies evolve through:
1. **Experience**: Direct interaction with tasks (`x`) and environment feedback (`f`).
2. **Reflection**: Leveraging cross-episode memory to generalize learnings.
3. **Internalization**: A deeper, abstracted learning phase (SFT) that strengthens the policy.
The flame icons on Policy components symbolize dynamic, adaptive processes. The Self-reflection phase (highlighted in orange) is critical for transferring knowledge between attempts, while Internalization (SFT) anchors the system in foundational learning. This structure aligns with RL principles but adds meta-cognitive layers (self-reflection) and cross-episode generalization, distinguishing it from standard RL frameworks.