\n
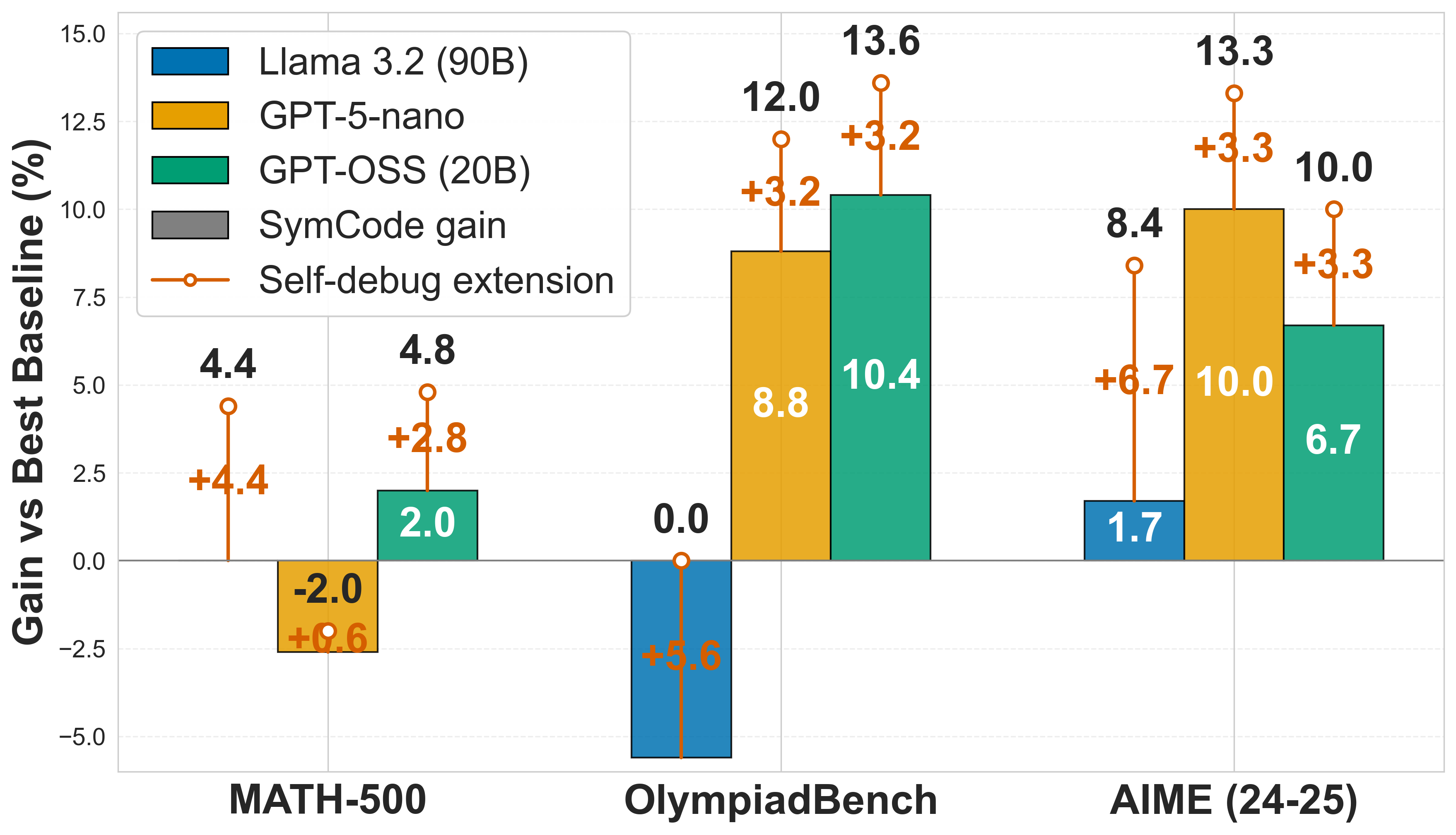
## Bar Chart: Performance Gain of Language Models on Math Benchmarks
### Overview
This bar chart compares the performance gain (in percentage) of three language models – Llama 3.2 (90B), GPT-5-nano, and GPT-OSS (20B) – on three math benchmarks: MATH-500, OlympiadBench, and AIME (24-25). It also shows the gains achieved by applying SymCode and a Self-debug extension to these models. The y-axis represents the "Gain vs Best Baseline (%)", while the x-axis represents the benchmarks.
### Components/Axes
* **Y-axis Title:** "Gain vs Best Baseline (%)" - Scale ranges from -5.0 to 15.0, with increments of 2.5.
* **X-axis Title:** Benchmarks: "MATH-500", "OlympiadBench", "AIME (24-25)".
* **Legend:** Located at the top-left corner.
* Blue: Llama 3.2 (90B)
* Orange: GPT-5-nano
* Green: GPT-OSS (20B)
* Red: SymCode gain
* Yellow/Orange circles: Self-debug extension
* **Data Representation:** Bar chart with overlaid data points for the Self-debug extension.
### Detailed Analysis
**MATH-500:**
* Llama 3.2 (90B): 4.4% gain.
* GPT-5-nano: 4.4% gain.
* GPT-OSS (20B): 2.0% gain.
* SymCode gain: -2.0% gain.
* Self-debug extension: 4.8% gain (+2.8% relative to baseline).
**OlympiadBench:**
* Llama 3.2 (90B): 0.0% gain.
* GPT-5-nano: 8.8% gain.
* GPT-OSS (20B): 10.4% gain.
* SymCode gain: 12.0% gain.
* Self-debug extension: 13.6% gain (+3.2% relative to baseline).
**AIME (24-25):**
* Llama 3.2 (90B): 1.7% gain.
* GPT-5-nano: 8.4% gain.
* GPT-OSS (20B): 6.7% gain.
* SymCode gain: 10.0% gain.
* Self-debug extension: 13.3% gain (+3.3% relative to baseline).
### Key Observations
* GPT-OSS (20B) consistently performs well on OlympiadBench and AIME (24-25), showing the highest gains on OlympiadBench.
* SymCode gain is negative on MATH-500, indicating a performance decrease when using SymCode on this benchmark.
* The Self-debug extension consistently improves performance across all three benchmarks, with the largest relative gain on OlympiadBench (+3.2%).
* Llama 3.2 (90B) shows relatively low gains across all benchmarks.
### Interpretation
The chart demonstrates the performance of different language models on various math problem-solving benchmarks. The results suggest that GPT-OSS (20B) is particularly effective at OlympiadBench and AIME, while GPT-5-nano and GPT-OSS (20B) perform similarly on MATH-500. The negative SymCode gain on MATH-500 is an anomaly that warrants further investigation – it could indicate that SymCode is not well-suited for the types of problems in this benchmark, or that it requires specific tuning. The consistent positive impact of the Self-debug extension suggests that this technique is a valuable addition to these models, improving their ability to solve math problems. The differences in performance across benchmarks highlight the importance of evaluating models on a diverse set of tasks to get a comprehensive understanding of their capabilities. The data suggests that model size (90B vs 20B) does not directly correlate with performance, as GPT-OSS (20B) often outperforms Llama 3.2 (90B).