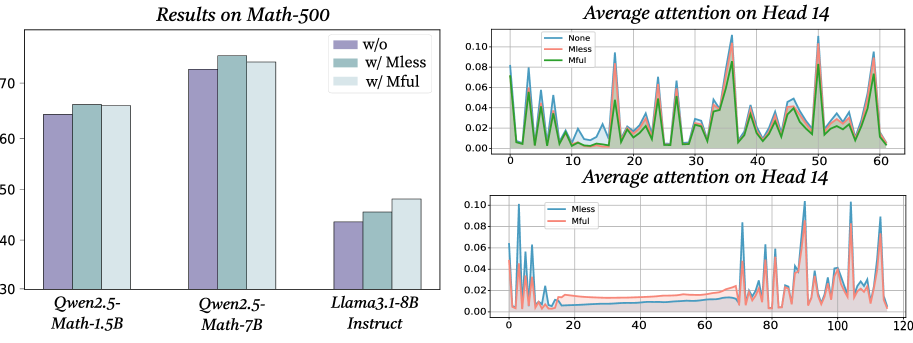
## Bar Chart: Results on Math-500
### Overview
The bar chart compares the performance of three language models (Qwen2.5-Math-1.5B, Qwen2.5-Math-7B, Llama3.1-8B Instruct) on the Math-500 benchmark. Three configurations are tested: baseline ("w/o"), with Mless attention ("w/ Mless"), and with Mful attention ("w/ Mful"). Performance is measured on a scale from 30 to 70.
### Components/Axes
- **X-axis**: Model variants (Qwen2.5-Math-1.5B, Qwen2.5-Math-7B, Llama3.1-8B Instruct)
- **Y-axis**: Performance score (30–70)
- **Legend**:
- Purple: "w/o" (baseline)
- Teal: "w/ Mless" (Mless attention)
- Light blue: "w/ Mful" (Mful attention)
### Detailed Analysis
- **Qwen2.5-Math-1.5B**:
- w/o: ~64
- w/ Mless: ~66
- w/ Mful: ~66
- **Qwen2.5-Math-7B**:
- w/o: ~73
- w/ Mless: ~75
- w/ Mful: ~74
- **Llama3.1-8B Instruct**:
- w/o: ~44
- w/ Mless: ~46
- w/ Mful: ~48
### Key Observations
- Larger models (Qwen2.5-Math-7B) outperform smaller models (Qwen2.5-Math-1.5B, Llama3.1-8B Instruct).
- Adding Mless attention improves performance across all models, with the largest gains in Qwen2.5-Math-7B (+2 points).
- Mful attention shows mixed results: it matches Mless for Qwen2.5-Math-1.5B but slightly underperforms for Qwen2.5-Math-7B.
### Interpretation
The chart suggests that Mless attention consistently enhances performance, particularly in larger models. Mful attention’s variable impact implies it may be less universally effective or context-dependent. The Llama3.1-8B Instruct model’s lower baseline performance highlights potential architectural or training differences.
---
## Line Graph: Average Attention on Head 14 (Full Range)
### Overview
This graph compares attention patterns across three mechanisms (None, Mless, Mful) in Head 14 of a neural network. The x-axis spans 0–60 tokens, and the y-axis measures attention magnitude (0–0.10).
### Components/Axes
- **X-axis**: Token positions (0–60)
- **Y-axis**: Attention magnitude (0–0.10)
- **Legend**:
- Blue: "None" (baseline)
- Red: "Mless"
- Green: "Mful"
### Detailed Analysis
- **Trends**:
- "Mful" (green) consistently shows higher peaks than "Mless" (red) and "None" (blue).
- "Mless" exhibits sharper, more frequent spikes than "None."
- All lines show periodic fluctuations, with "Mful" maintaining the highest average attention.
### Key Observations
- "Mful" attention dominates in Head 14, suggesting it prioritizes critical tokens more effectively.
- "None" (baseline) has the lowest and most erratic attention distribution.
### Interpretation
The dominance of "Mful" attention in Head 14 aligns with its performance improvements in the Math-500 results. This implies that Mful’s attention mechanism may better focus on relevant mathematical reasoning tokens, enhancing model accuracy.
---
## Line Graph: Average Attention on Head 14 (Extended Range)
### Overview
A zoomed-out version of the previous graph, extending the x-axis to 120 tokens. Compares "Mless" (blue) and "Mful" (red) attention mechanisms.
### Components/Axes
- **X-axis**: Token positions (0–120)
- **Y-axis**: Attention magnitude (0–0.10)
- **Legend**:
- Blue: "Mless"
- Red: "Mful"
### Detailed Analysis
- **Trends**:
- "Mful" (red) maintains higher attention values than "Mless" (blue) across the extended range.
- Both lines show cyclical patterns, but "Mful" peaks are more pronounced and sustained.
### Key Observations
- The extended range confirms "Mful"’s consistent superiority over "Mless," even beyond the initial 60-token window.
- "Mless" attention decays more rapidly after token position 60.
### Interpretation
The extended analysis reinforces that "Mful" attention provides a more stable and focused mechanism, likely contributing to its performance advantages in mathematical tasks. The decay in "Mless" attention suggests it may struggle with long-range dependencies.
---
## Cross-Referenced Insights
1. **Attention Mechanism Impact**: Both line graphs confirm that "Mful" attention correlates with improved Math-500 performance, validating its effectiveness in prioritizing critical tokens.
2. **Model-Attention Synergy**: Larger models (Qwen2.5-Math-7B) benefit most from Mless attention, indicating that model size and attention mechanism interact to optimize performance.
3. **Llama3.1-8B Instruct Limitations**: Despite being the largest model, its lower baseline performance suggests architectural or training differences that Mless/Mful attention cannot fully mitigate.
## Conclusion
The data demonstrates that Mless and Mful attention mechanisms enhance mathematical reasoning capabilities, with Mful showing the strongest and most consistent impact. These findings highlight the importance of attention design in language models for specialized tasks like math problem-solving.