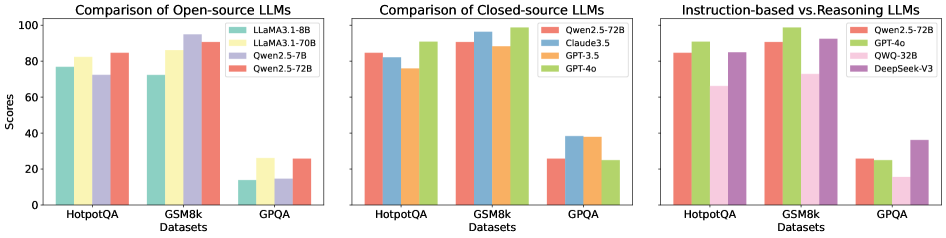
## Bar Charts: Comparison of LLMs Across Datasets
### Overview
The image contains three grouped bar charts comparing the performance of various large language models (LLMs) across three datasets: HotpotQA, GSM8k, and GPQA. Each chart focuses on a different category of LLMs: open-source, closed-source, and instruction-based vs. reasoning models. Scores range from 0 to 100 on the y-axis, with datasets on the x-axis.
---
### Components/Axes
#### Labels and Legends
1. **First Chart (Open-source LLMs):**
- **Legend:**
- LLaMA 3.1-8B (green)
- LLaMA 3.1-70B (yellow)
- Qwen2.5-7B (purple)
- Qwen2.5-72B (red)
- **X-axis:** HotpotQA, GSM8k, GPQA
- **Y-axis:** Scores (0–100)
2. **Second Chart (Closed-source LLMs):**
- **Legend:**
- Qwen2.5-72B (red)
- Claude3.5 (blue)
- GPT-3.5 (orange)
- GPT-4o (green)
- **X-axis:** HotpotQA, GSM8k, GPQA
- **Y-axis:** Scores (0–100)
3. **Third Chart (Instruction-based vs. Reasoning LLMs):**
- **Legend:**
- Qwen2.5-72B (red)
- GPT-4o (green)
- QWQ-32B (pink)
- DeepSeek-V3 (purple)
- **X-axis:** HotpotQA, GSM8k, GPQA
- **Y-axis:** Scores (0–100)
---
### Detailed Analysis
#### First Chart (Open-source LLMs)
- **HotpotQA:**
- LLaMA 3.1-70B: ~85
- Qwen2.5-72B: ~83
- LLaMA 3.1-8B: ~78
- Qwen2.5-7B: ~72
- **GSM8k:**
- LLaMA 3.1-70B: ~95
- Qwen2.5-72B: ~90
- LLaMA 3.1-8B: ~75
- Qwen2.5-7B: ~15
- **GPQA:**
- LLaMA 3.1-70B: ~25
- Qwen2.5-72B: ~25
- Qwen2.5-7B: ~25
- LLaMA 3.1-8B: ~15
#### Second Chart (Closed-source LLMs)
- **HotpotQA:**
- Qwen2.5-72B: ~85
- GPT-4o: ~80
- Claude3.5: ~75
- GPT-3.5: ~70
- **GSM8k:**
- Qwen2.5-72B: ~95
- GPT-4o: ~90
- Claude3.5: ~85
- GPT-3.5: ~80
- **GPQA:**
- Qwen2.5-72B: ~25
- GPT-4o: ~25
- Claude3.5: ~25
- GPT-3.5: ~25
#### Third Chart (Instruction-based vs. Reasoning LLMs)
- **HotpotQA:**
- Qwen2.5-72B: ~85
- GPT-4o: ~80
- QWQ-32B: ~70
- DeepSeek-V3: ~65
- **GSM8k:**
- Qwen2.5-72B: ~95
- GPT-4o: ~90
- DeepSeek-V3: ~85
- QWQ-32B: ~70
- **GPQA:**
- Qwen2.5-72B: ~25
- GPT-4o: ~25
- DeepSeek-V3: ~35
- QWQ-32B: ~20
---
### Key Observations
1. **Open-source LLMs:**
- Larger models (e.g., LLaMA 3.1-70B) outperform smaller variants (e.g., LLaMA 3.1-8B) across all datasets.
- Qwen2.5-72B consistently outperforms Qwen2.5-7B, especially in GPQA.
2. **Closed-source LLMs:**
- Qwen2.5-72B and GPT-4o dominate performance metrics, with Qwen2.5-72B leading in GSM8k and GPQA.
- GPT-3.5 and Claude3.5 show similar scores but lag behind Qwen2.5-72B and GPT-4o.
3. **Instruction-based vs. Reasoning LLMs:**
- Instruction-based models (Qwen2.5-72B, GPT-4o) outperform reasoning models (DeepSeek-V3, QWQ-32B) in HotpotQA and GSM8k.
- DeepSeek-V3 surpasses QWQ-32B in GPQA, suggesting reasoning models may excel in specific tasks.
---
### Interpretation
- **Model Size Matters:** Larger models (e.g., 70B parameters) generally achieve higher scores, particularly in complex tasks like GPQA.
- **Closed-source Advantage:** Qwen2.5-72B and GPT-4o consistently outperform open-source models, highlighting potential advantages in proprietary architectures or training data.
- **Instruction-tuning Impact:** Instruction-based models (Qwen2.5-72B, GPT-4o) excel in reasoning tasks, while reasoning models (DeepSeek-V3) show niche strengths in GPQA.
- **Anomalies:** Qwen2.5-7B underperforms significantly in GSM8k (~15 vs. ~95 for LLaMA 3.1-70B), suggesting task-specific limitations.
The data underscores the importance of model scale, architecture, and training methodology in LLM performance across diverse benchmarks.