## Bar Chart: Computational Cost Comparison in LLaMA-7B
### Overview
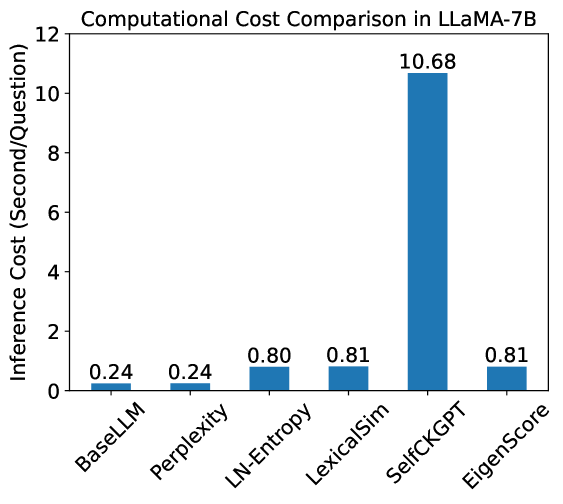
The image is a bar chart comparing the computational cost (inference cost in seconds per question) of different methods in LLaMA-7B. The x-axis represents the methods, and the y-axis represents the inference cost.
### Components/Axes
* **Title:** Computational Cost Comparison in LLaMA-7B
* **X-axis:** Methods (BaseLLM, Perplexity, LN-Entropy, LexicalSim, SelfCKGPT, EigenScore)
* **Y-axis:** Inference Cost (Second/Question), with a scale from 0 to 12.
* **Bars:** Each bar represents a method, with its height corresponding to the inference cost. The bars are all the same color: blue.
### Detailed Analysis
The chart displays the inference cost for each method. The values are as follows:
* **BaseLLM:** 0.24 seconds/question
* **Perplexity:** 0.24 seconds/question
* **LN-Entropy:** 0.80 seconds/question
* **LexicalSim:** 0.81 seconds/question
* **SelfCKGPT:** 10.68 seconds/question
* **EigenScore:** 0.81 seconds/question
### Key Observations
* SelfCKGPT has a significantly higher inference cost (10.68 seconds/question) compared to the other methods.
* BaseLLM and Perplexity have the lowest inference costs, both at 0.24 seconds/question.
* LN-Entropy, LexicalSim, and EigenScore have similar inference costs, around 0.80-0.81 seconds/question.
### Interpretation
The chart demonstrates that SelfCKGPT is computationally much more expensive than the other methods when used with LLaMA-7B. BaseLLM and Perplexity are the most efficient in terms of inference cost. The other methods (LN-Entropy, LexicalSim, and EigenScore) have similar, moderate inference costs. This suggests that SelfCKGPT might involve more complex computations or require more resources during inference.