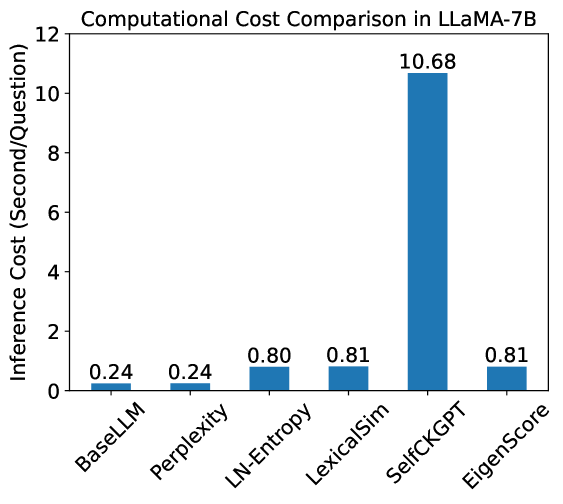
## Bar Chart: Computational Cost Comparison in LLaMA-7B
### Overview
This image is a vertical bar chart titled "Computational Cost Comparison in LLaMA-7B." It compares the inference time, measured in seconds per question, across six different computational methods or metrics applied to the LLaMA-7B large language model. The chart highlights a significant disparity in computational requirements between the various methods.
### Components/Axes
* **Header (Title):** "Computational Cost Comparison in LLaMA-7B" is centered at the top.
* **Y-Axis (Vertical):**
* **Label:** "Inference Cost (Second/Question)" positioned on the left.
* **Scale:** Ranges from 0 to 12.
* **Major Tick Marks:** Placed at intervals of 2 (0, 2, 4, 6, 8, 10, 12).
* **X-Axis (Horizontal):**
* **Categories:** Six distinct labels representing different methods, rotated approximately 45 degrees for readability. From left to right: `BaseLLM`, `Perplexity`, `LN-Entropy`, `LexicalSim`, `SelfCKGPT`, and `EigenScore`.
* **Data Representation:** Six blue bars, each with a numerical value label positioned directly above the bar.
* **Legend:** No explicit legend is present as there is only one data series (Inference Cost).
### Content Details
The chart displays the following precise data points for inference cost (seconds/question):
| Category | Visual Trend | Value (Seconds/Question) |
| :--- | :--- | :--- |
| **BaseLLM** | Baseline low level | 0.24 |
| **Perplexity** | Flat relative to baseline | 0.24 |
| **LN-Entropy** | Slight upward step | 0.80 |
| **LexicalSim** | Nearly identical to previous | 0.81 |
| **SelfCKGPT** | Massive vertical spike | 10.68 |
| **EigenScore** | Sharp drop back to low level | 0.81 |
### Key Observations
* **Extreme Outlier:** `SelfCKGPT` is a massive outlier, with a cost of 10.68 seconds per question. This is approximately 44.5 times the cost of the `BaseLLM` baseline.
* **Baseline Group:** `BaseLLM` and `Perplexity` share the lowest computational cost at exactly 0.24 seconds per question, suggesting that calculating Perplexity adds negligible overhead to standard inference.
* **Moderate Overhead Group:** `LN-Entropy`, `LexicalSim`, and `EigenScore` form a cluster with very similar costs, ranging from 0.80 to 0.81 seconds per question. These methods represent roughly a 3.3x increase in cost over the baseline.
* **Symmetry:** The chart shows a relatively flat profile for the first four categories, a huge peak at the fifth, and a return to the moderate level for the final category.
### Interpretation
The data demonstrates the trade-offs between different evaluation or uncertainty-quantification metrics for the LLaMA-7B model.
1. **Efficiency of Traditional Metrics:** Metrics like `Perplexity` are highly efficient, adding no measurable time to the base inference process.
2. **Cost of Advanced Heuristics:** Methods like `LN-Entropy`, `LexicalSim`, and `EigenScore` likely involve additional post-processing or internal state analysis that triples the time required per question compared to a raw model call.
3. **The "Self-Checking" Penalty:** The `SelfCKGPT` method is prohibitively expensive for real-time applications. Given the name and the magnitude of the cost (over 10 seconds), it likely involves a "self-correction" or "multi-path" reasoning process where the model generates multiple responses or queries itself several times to verify an answer, effectively multiplying the inference cycles required for a single output.
4. **Practical Application:** For high-throughput systems, `EigenScore` or `LexicalSim` might be the upper limit of acceptable overhead, while `SelfCKGPT` would likely be reserved for offline evaluation or tasks where accuracy is far more critical than latency.