\n
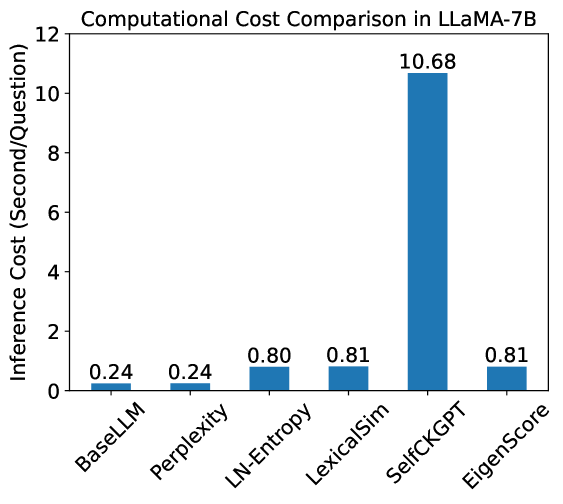
## Bar Chart: Computational Cost Comparison in LLaMA-7B
### Overview
This bar chart compares the inference cost (in seconds/question) of several methods when used with the LLaMA-7B language model. The methods being compared are BaseLLM, Perplexity, LN-Entropy, LexicalSim, SelfCKGPT, and EigenScore. The inference cost is represented by the height of each bar.
### Components/Axes
* **Title:** Computational Cost Comparison in LLaMA-7B
* **X-axis:** Method Name (BaseLLM, Perplexity, LN-Entropy, LexicalSim, SelfCKGPT, EigenScore)
* **Y-axis:** Inference Cost (Second/Question), ranging from 0 to 12.
* **Data Series:** Single series representing the inference cost for each method.
* **Data Labels:** Numerical values displayed above each bar, indicating the inference cost.
### Detailed Analysis
The chart displays six bars, each representing a different method.
* **BaseLLM:** The bar for BaseLLM is very short, with an inference cost of approximately 0.24 seconds/question.
* **Perplexity:** The bar for Perplexity is the same height as BaseLLM, with an inference cost of approximately 0.24 seconds/question.
* **LN-Entropy:** The bar for LN-Entropy is taller than BaseLLM and Perplexity, with an inference cost of approximately 0.80 seconds/question.
* **LexicalSim:** The bar for LexicalSim is similar in height to LN-Entropy, with an inference cost of approximately 0.81 seconds/question.
* **SelfCKGPT:** The bar for SelfCKGPT is significantly taller than all other bars, with an inference cost of approximately 10.68 seconds/question.
* **EigenScore:** The bar for EigenScore is similar in height to LN-Entropy and LexicalSim, with an inference cost of approximately 0.81 seconds/question.
### Key Observations
* SelfCKGPT has a dramatically higher inference cost than all other methods.
* BaseLLM and Perplexity have the lowest inference costs, and are identical.
* LN-Entropy, LexicalSim, and EigenScore have similar inference costs, which are significantly higher than BaseLLM and Perplexity, but much lower than SelfCKGPT.
### Interpretation
The data suggests that SelfCKGPT is substantially more computationally expensive to use with LLaMA-7B than the other methods tested. This could be due to the complexity of the SelfCKGPT algorithm or the amount of data it processes. BaseLLM and Perplexity are the most efficient methods, suggesting they require the least computational resources. The similar costs of LN-Entropy, LexicalSim, and EigenScore indicate they offer a trade-off between computational cost and potentially different performance characteristics.
The chart highlights the importance of considering computational cost when choosing a method for use with large language models like LLaMA-7B. While some methods may offer better performance, they may come at a significant computational cost, making them impractical for certain applications. The large difference in cost between SelfCKGPT and the other methods suggests that it may only be suitable for applications where performance is critical and computational resources are not a constraint.