\n
## Pie Charts: Performance Breakdown by Dataset
### Overview
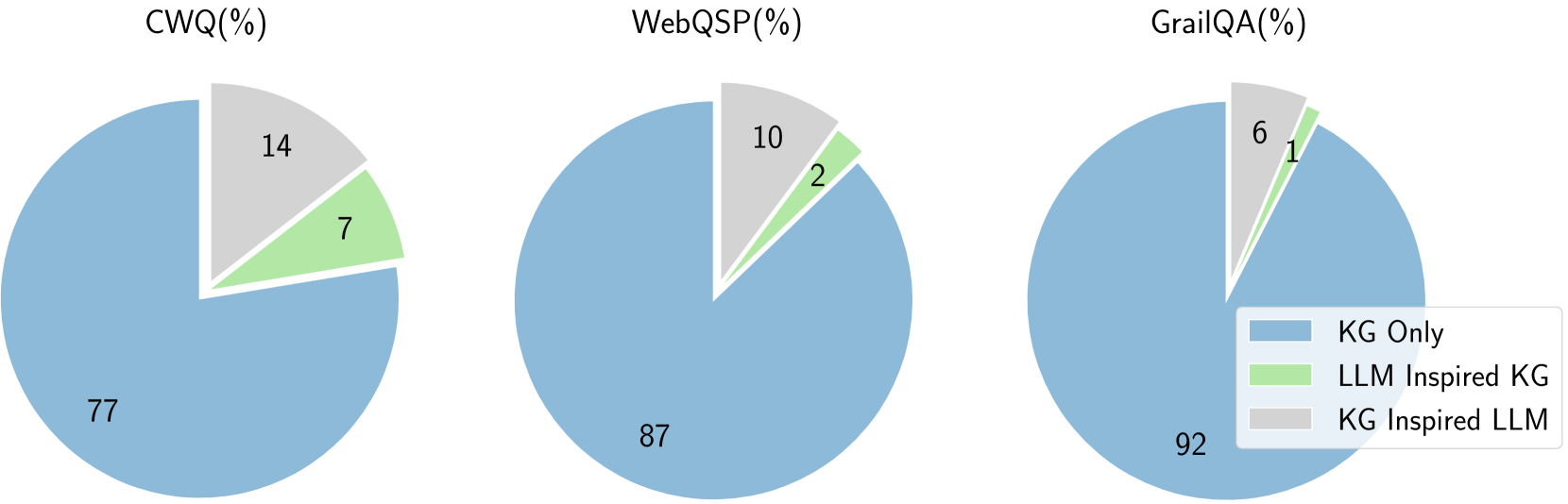
The image presents three pie charts, each representing the performance breakdown across different datasets: CWQ, WebQSP, and GrailQA. The performance is categorized into three approaches: "KG Only", "LLM Inspired KG", and "KG Inspired LLM". All values are expressed as percentages.
### Components/Axes
Each chart has a title indicating the dataset name followed by "(%)". A legend is positioned in the bottom-right corner, defining the color-coding for each approach:
* **KG Only:** Light Blue
* **LLM Inspired KG:** Light Green
* **KG Inspired LLM:** Light Grey
Each pie chart displays percentage values directly on the slices.
### Detailed Analysis or Content Details
**CWQ (%)**
* **KG Only:** 77% - Largest slice, occupying the majority of the pie chart.
* **LLM Inspired KG:** 14% - Second largest slice.
* **KG Inspired LLM:** 7% - Smallest slice.
**WebQSP (%)**
* **KG Only:** 87% - Dominant slice, representing the vast majority of the pie chart.
* **LLM Inspired KG:** 10% - Second largest slice.
* **KG Inspired LLM:** 2% - Smallest slice.
**GrailQA (%)**
* **KG Only:** 92% - Largest slice, almost the entire pie chart.
* **LLM Inspired KG:** 6% - Second largest slice.
* **KG Inspired LLM:** 1% - Very small slice.
### Key Observations
Across all three datasets, the "KG Only" approach consistently outperforms the other two methods by a significant margin. The "LLM Inspired KG" approach performs better than the "KG Inspired LLM" approach in all cases, but the difference is more pronounced in the WebQSP and GrailQA datasets. The "KG Inspired LLM" approach consistently has the lowest performance across all datasets.
### Interpretation
The data suggests that, for these datasets (CWQ, WebQSP, and GrailQA), relying solely on Knowledge Graphs ("KG Only") yields the best results. While incorporating Large Language Models (LLMs) to enhance the Knowledge Graph ("LLM Inspired KG") provides some improvement over the "KG Inspired LLM" approach, it does not reach the performance level of the "KG Only" method. This could indicate that the LLMs are not effectively contributing to the knowledge graph's performance in these specific scenarios, or that the current implementation of LLM integration is suboptimal. The consistent dominance of the "KG Only" approach highlights the strength of knowledge graph-based methods for these question answering tasks. The relatively small contributions of LLM-inspired methods suggest that further research is needed to effectively leverage LLMs in conjunction with knowledge graphs for improved performance.