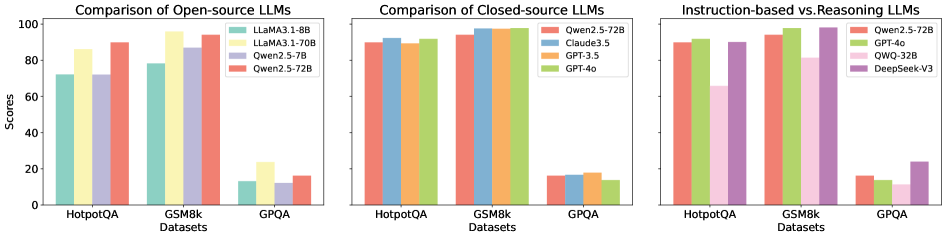
## Bar Chart: LLM Performance Comparison
### Overview
The image presents a comparative analysis of Large Language Models (LLMs) across three datasets: HotpotQA, GSM8k, and GPQA. It consists of three separate bar charts, each focusing on a different category of LLMs: Open-source LLMs, Closed-source LLMs, and a comparison between Instruction-based and Reasoning LLMs. The y-axis represents "Scores," ranging from 0 to 100. The x-axis represents the datasets used for evaluation.
### Components/Axes
* **Y-axis:** "Scores" (Scale: 0 to 100, increments of 20)
* **X-axis:** "Datasets" (Categories: HotpotQA, GSM8k, GPQA)
* **Chart 1 (Open-source LLMs):**
* Legend:
* Light Blue: LLaMA3-8B
* Yellow: LLaMA3-70B
* Light Green: Qwen2.5-7B
* Red: Qwen2.5-72B
* **Chart 2 (Closed-source LLMs):**
* Legend:
* Light Green: Qwen2.5-72B
* Purple: Claude3.5
* Orange: GPT-3.5
* Red: GPT-4o
* **Chart 3 (Instruction-based vs. Reasoning LLMs):**
* Legend:
* Purple: Qwen2.5-72B
* Orange: GPT-4o
* Light Green: QWO-32B
* Dark Green: DeepSeek-V3
### Detailed Analysis or Content Details
**Chart 1: Comparison of Open-source LLMs**
* **HotpotQA:**
* LLaMA3-8B: Approximately 70
* LLaMA3-70B: Approximately 82
* Qwen2.5-7B: Approximately 78
* Qwen2.5-72B: Approximately 88
* **GSM8k:**
* LLaMA3-8B: Approximately 80
* LLaMA3-70B: Approximately 90
* Qwen2.5-7B: Approximately 85
* Qwen2.5-72B: Approximately 92
* **GPQA:**
* LLaMA3-8B: Approximately 12
* LLaMA3-70B: Approximately 20
* Qwen2.5-7B: Approximately 15
* Qwen2.5-72B: Approximately 18
**Chart 2: Comparison of Closed-source LLMs**
* **HotpotQA:**
* Qwen2.5-72B: Approximately 92
* Claude3.5: Approximately 94
* GPT-3.5: Approximately 90
* GPT-4o: Approximately 96
* **GSM8k:**
* Qwen2.5-72B: Approximately 92
* Claude3.5: Approximately 95
* GPT-3.5: Approximately 90
* GPT-4o: Approximately 97
* **GPQA:**
* Qwen2.5-72B: Approximately 18
* Claude3.5: Approximately 16
* GPT-3.5: Approximately 14
* GPT-4o: Approximately 19
**Chart 3: Instruction-based vs. Reasoning LLMs**
* **HotpotQA:**
* Qwen2.5-72B: Approximately 88
* GPT-4o: Approximately 96
* QWO-32B: Approximately 84
* DeepSeek-V3: Approximately 80
* **GSM8k:**
* Qwen2.5-72B: Approximately 92
* GPT-4o: Approximately 97
* QWO-32B: Approximately 88
* DeepSeek-V3: Approximately 85
* **GPQA:**
* Qwen2.5-72B: Approximately 18
* GPT-4o: Approximately 19
* QWO-32B: Approximately 12
* DeepSeek-V3: Approximately 10
### Key Observations
* GPT-4o consistently achieves the highest scores across all datasets in both the Closed-source and Instruction-based/Reasoning LLM charts.
* Qwen2.5-72B performs well across all datasets, often outperforming other open-source models.
* LLaMA3-70B generally outperforms LLaMA3-8B.
* GPQA consistently yields the lowest scores across all models, indicating it is the most challenging dataset.
* Claude3.5 consistently performs slightly lower than GPT-4o, but higher than GPT-3.5.
### Interpretation
The data suggests that GPT-4o is currently the leading LLM in terms of performance on these datasets. The closed-source models generally outperform the open-source models, although Qwen2.5-72B demonstrates strong performance within the open-source category. The varying performance across datasets highlights the importance of evaluating LLMs on a diverse range of tasks. The consistently low scores on GPQA suggest that this dataset presents a unique challenge for current LLMs, potentially requiring specialized training or architectural improvements. The comparison between instruction-based and reasoning LLMs shows that GPT-4o and Qwen2.5-72B are strong performers in both areas, while QWO-32B and DeepSeek-V3 show slightly lower, but still competitive, results. The trends indicate a positive correlation between model size (e.g., LLaMA3-70B vs. LLaMA3-8B) and performance.