## Bar Charts: LLM Performance Comparison Across Datasets
### Overview
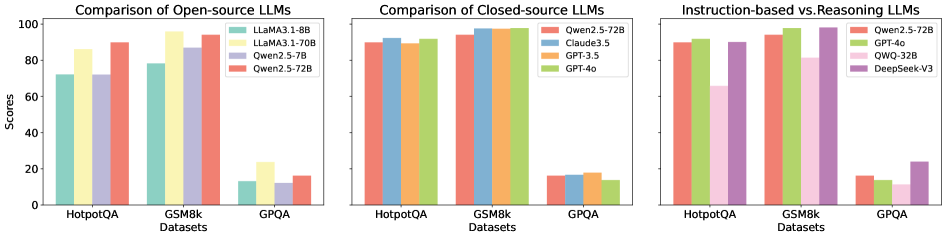
The image displays three side-by-side grouped bar charts comparing the performance scores of various Large Language Models (LLMs) on three distinct datasets: HotpotQA, GSM8k, and GPQA. The charts are categorized by model type: open-source, closed-source, and instruction-based vs. reasoning-based. All charts share a common y-axis labeled "Scores" ranging from 0 to 100.
### Components/Axes
* **Chart 1 (Left):** "Comparison of Open-source LLMs"
* **X-axis (Datasets):** HotpotQA, GSM8k, GPQA.
* **Y-axis:** Scores (0-100).
* **Legend (Top-Right):**
* Teal bar: LLaMA3.1-8B
* Yellow bar: LLaMA3.1-70B
* Light Purple bar: Qwen2.5-7B
* Salmon/Red bar: Qwen2.5-72B
* **Chart 2 (Center):** "Comparison of Closed-source LLMs"
* **X-axis (Datasets):** HotpotQA, GSM8k, GPQA.
* **Y-axis:** Scores (0-100).
* **Legend (Top-Left):**
* Salmon/Red bar: Qwen2.5-72B *(Note: This model also appears in the open-source chart)*
* Blue bar: Claude3.5
* Orange bar: GPT-3.5
* Green bar: GPT-4o
* **Chart 3 (Right):** "Instruction-based vs. Reasoning LLMs"
* **X-axis (Datasets):** HotpotQA, GSM8k, GPQA.
* **Y-axis:** Scores (0-100).
* **Legend (Top-Right):**
* Salmon/Red bar: Qwen2.5-72B
* Light Green bar: GPT-4o
* Pink bar: QWO-32B
* Purple bar: DeepSeek-V3
### Detailed Analysis
**Chart 1: Open-source LLMs**
* **HotpotQA:** LLaMA3.1-70B (Yellow) scores highest (~85), followed by Qwen2.5-72B (Salmon, ~75), LLaMA3.1-8B (Teal, ~70), and Qwen2.5-7B (Purple, ~68).
* **GSM8k:** All models show significantly higher performance. Qwen2.5-72B (Salmon) leads (~95), closely followed by LLaMA3.1-70B (Yellow, ~92), Qwen2.5-7B (Purple, ~88), and LLaMA3.1-8B (Teal, ~78).
* **GPQA:** Performance drops drastically for all models. LLaMA3.1-70B (Yellow) is highest (~22), followed by Qwen2.5-72B (Salmon, ~15), LLaMA3.1-8B (Teal, ~12), and Qwen2.5-7B (Purple, ~10).
**Chart 2: Closed-source LLMs**
* **HotpotQA:** Claude3.5 (Blue) and GPT-4o (Green) are nearly tied at the top (~90), with Qwen2.5-72B (Salmon, ~88) and GPT-3.5 (Orange, ~85) slightly behind.
* **GSM8k:** All models perform exceptionally well, clustered near the top. GPT-4o (Green) appears marginally highest (~98), with the others (Claude3.5, GPT-3.5, Qwen2.5-72B) all above ~95.
* **GPQA:** Scores are uniformly low. GPT-3.5 (Orange) is highest (~18), followed by Claude3.5 (Blue, ~17), GPT-4o (Green, ~15), and Qwen2.5-72B (Salmon, ~14).
**Chart 3: Instruction-based vs. Reasoning LLMs**
* **HotpotQA:** GPT-4o (Light Green) and Qwen2.5-72B (Salmon) are top (~90), followed by DeepSeek-V3 (Purple, ~88) and QWO-32B (Pink, ~65).
* **GSM8k:** GPT-4o (Light Green) and Qwen2.5-72B (Salmon) again lead (~95), with DeepSeek-V3 (Purple, ~80) and QWO-32B (Pink, ~78) following.
* **GPQA:** DeepSeek-V3 (Purple) shows a notable relative performance (~25), significantly higher than the others: Qwen2.5-72B (Salmon, ~15), GPT-4o (Light Green, ~12), and QWO-32B (Pink, ~10).
### Key Observations
1. **Dataset Difficulty:** GPQA is consistently the most challenging dataset for all model types, with scores rarely exceeding 25. GSM8k is the easiest, with top models scoring near 100.
2. **Model Scaling:** Within the open-source chart, the 70B/72B parameter models (LLaMA3.1-70B, Qwen2.5-72B) consistently outperform their smaller 7B/8B counterparts.
3. **Closed-source Dominance:** The closed-source models (Chart 2) generally achieve higher scores on HotpotQA and GSM8k compared to the open-source models (Chart 1).
4. **Notable Outlier:** In Chart 3, DeepSeek-V3 (Purple) demonstrates a uniquely strong performance on the difficult GPQA dataset compared to the other models in its group.
5. **Model Consistency:** Qwen2.5-72B (Salmon) appears in all three charts, serving as a common reference point. Its performance is strong but not always the absolute top in the closed-source category.
### Interpretation
The data suggests a clear hierarchy of task difficulty, with GPQA representing a significant challenge frontier for current LLMs. The performance gap between open-source and closed-source models, while present, is less pronounced on the easiest task (GSM8k) and the hardest task (GPQA), indicating that scaling and architecture advantages of closed models are most evident on mid-difficulty reasoning tasks like HotpotQA.
The inclusion of Qwen2.5-72B across all charts allows for a cross-category comparison. It performs competitively with top closed-source models, suggesting it is a high-performing open-source option. The standout performance of DeepSeek-V3 on GPQA in the third chart hints at potential architectural or training differences that may confer an advantage on that specific type of complex reasoning task, warranting further investigation into its design. Overall, the charts illustrate that model performance is highly dependent on both the model's scale/type and the specific nature of the evaluation dataset.