\n
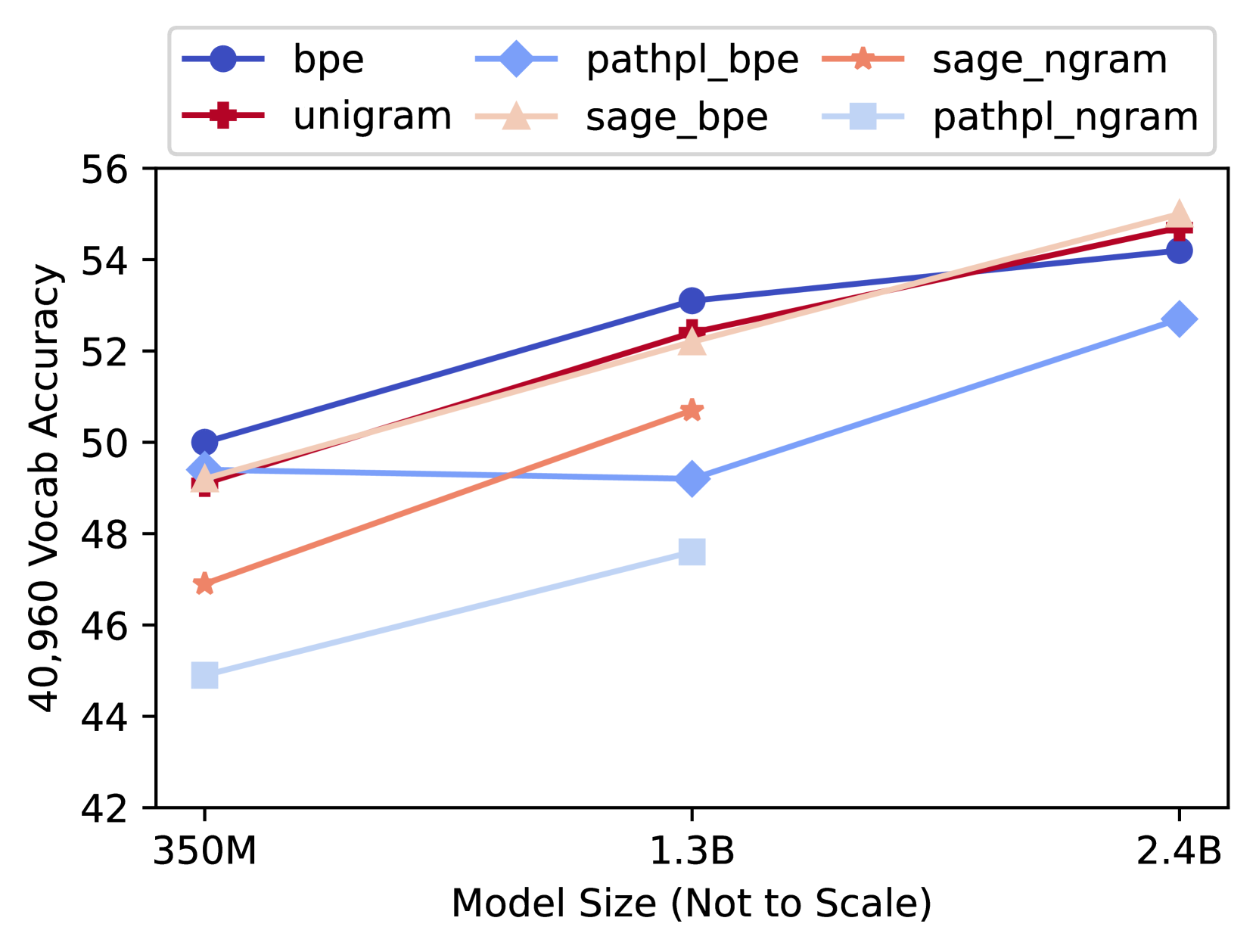
## Line Chart: Vocab Accuracy vs. Model Size
### Overview
This line chart depicts the relationship between model size and vocabulary accuracy for six different tokenization methods. The x-axis represents model size, and the y-axis represents vocabulary accuracy. The chart shows how accuracy changes as model size increases for each method.
### Components/Axes
* **X-axis Title:** "Model Size (Not to Scale)"
* **X-axis Markers:** 350M, 1.3B, 2.4B
* **Y-axis Title:** "40,960 Vocab Accuracy"
* **Y-axis Scale:** Ranges from approximately 42 to 56.
* **Legend:** Located at the top-center of the chart.
* bpe (Blue)
* pathpl\_bpe (Light Blue)
* sage\_ngram (Orange)
* unigram (Red)
* sage\_bpe (Pink)
* pathpl\_ngram (Gray)
### Detailed Analysis
The chart displays six lines, each representing a different tokenization method.
* **bpe (Blue):** The line slopes upward, starting at approximately 49.8 at 350M, rising to approximately 53.5 at 1.3B, and reaching approximately 54.2 at 2.4B.
* **pathpl\_bpe (Light Blue):** The line shows a steady, but relatively slow, upward trend. It begins at approximately 44.8 at 350M, increases to approximately 47.5 at 1.3B, and reaches approximately 52.3 at 2.4B.
* **sage\_ngram (Orange):** The line exhibits an upward trend, starting at approximately 47.8 at 350M, increasing to approximately 50.2 at 1.3B, and reaching approximately 51.2 at 2.4B.
* **unigram (Red):** The line slopes upward, starting at approximately 49.5 at 350M, rising to approximately 52.6 at 1.3B, and reaching approximately 53.8 at 2.4B.
* **sage\_bpe (Pink):** The line shows a moderate upward trend, starting at approximately 48.5 at 350M, increasing to approximately 50.5 at 1.3B, and reaching approximately 51.5 at 2.4B.
* **pathpl\_ngram (Gray):** The line shows a slow upward trend, starting at approximately 46.5 at 350M, increasing to approximately 47.2 at 1.3B, and reaching approximately 48.5 at 2.4B.
### Key Observations
* The 'bpe' method consistently demonstrates the highest vocabulary accuracy across all model sizes.
* 'pathpl\_bpe' consistently shows the lowest vocabulary accuracy.
* All methods show an increase in accuracy as model size increases, but the rate of increase varies.
* The differences in accuracy between methods become more pronounced at larger model sizes (2.4B).
### Interpretation
The data suggests that the choice of tokenization method significantly impacts vocabulary accuracy, particularly as model size grows. The 'bpe' method appears to be the most effective for achieving high vocabulary accuracy, while 'pathpl\_bpe' is the least effective. The consistent upward trend for all methods indicates that increasing model size generally improves vocabulary accuracy, but the marginal benefit diminishes as the model becomes larger. The relatively small differences in accuracy between some methods (e.g., 'unigram', 'sage\_bpe', 'sage\_ngram') at smaller model sizes suggest that other factors may become more important as model size increases. The "Not to Scale" disclaimer on the x-axis implies that the distances between model sizes are not proportional to the actual differences in size, and should be interpreted cautiously. This chart is likely used to evaluate and compare different tokenization strategies for language models.