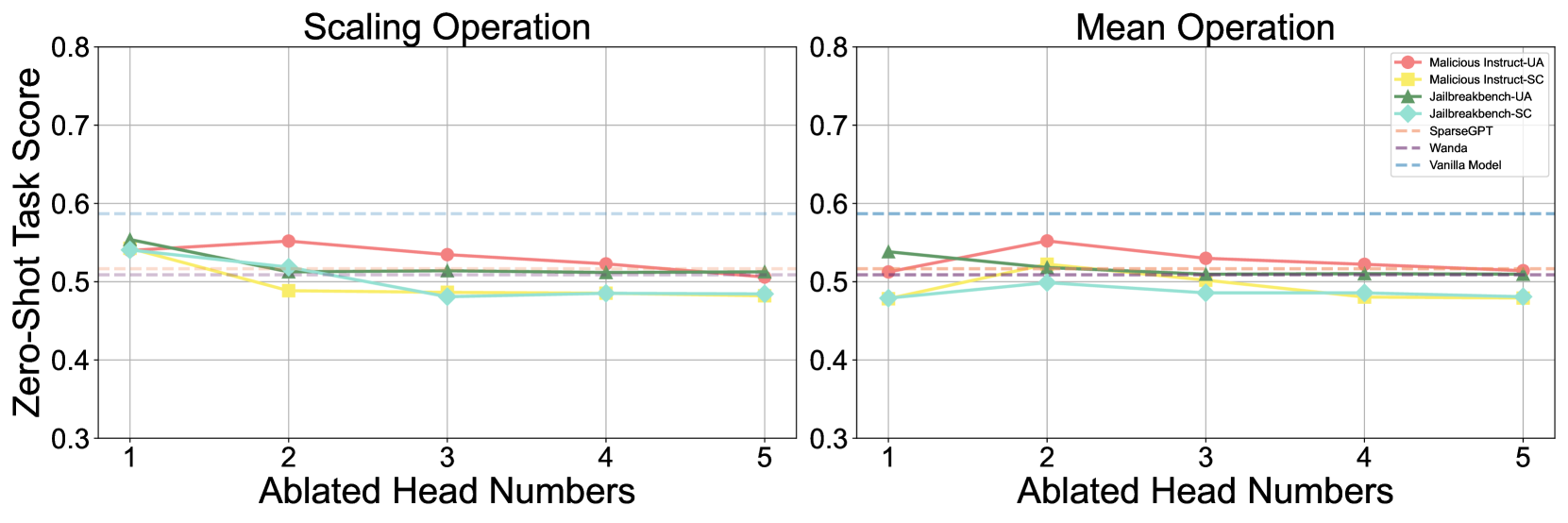
## Line Chart: Zero-Shot Task Score vs. Ablated Head Numbers
### Overview
The image presents two line charts comparing the performance of different models on a zero-shot task, as measured by "Zero-Shot Task Score," against the number of "Ablated Head Numbers." The left chart focuses on "Scaling Operation" while the right chart focuses on "Mean Operation." Each chart displays the performance of several models, indicated by different colored lines, as the number of ablated heads increases from 1 to 5. The charts are visually similar, with the same x-axis and y-axis scales.
### Components/Axes
* **X-axis:** "Ablated Head Numbers" - Scale ranges from 1 to 5.
* **Y-axis:** "Zero-Shot Task Score" - Scale ranges from 0.3 to 0.8.
* **Left Chart Title:** "Scaling Operation"
* **Right Chart Title:** "Mean Operation"
* **Legend (Top-Right of Right Chart):**
* Malicious Instruct-UA (Red)
* Malicious Instruct-SC (Orange)
* Jailbreakbench-UA (Light Green)
* Jailbreakbench-SC (Dark Green)
* SparseGPT (Purple)
* Wanda (Blue)
* Vanilla Model (Light Blue, dashed)
### Detailed Analysis or Content Details
**Left Chart - Scaling Operation:**
* **Malicious Instruct-UA (Red):** Starts at approximately 0.54 at Ablated Head Numbers = 1, dips to approximately 0.51 at Ablated Head Numbers = 2, rises to approximately 0.56 at Ablated Head Numbers = 3, then declines to approximately 0.52 at Ablated Head Numbers = 5.
* **Malicious Instruct-SC (Orange):** Starts at approximately 0.53 at Ablated Head Numbers = 1, remains relatively stable around 0.52-0.53 up to Ablated Head Numbers = 4, and then decreases to approximately 0.50 at Ablated Head Numbers = 5.
* **Jailbreakbench-UA (Light Green):** Starts at approximately 0.48 at Ablated Head Numbers = 1, increases to approximately 0.52 at Ablated Head Numbers = 2, then decreases to approximately 0.48 at Ablated Head Numbers = 5.
* **Jailbreakbench-SC (Dark Green):** Starts at approximately 0.46 at Ablated Head Numbers = 1, increases to approximately 0.49 at Ablated Head Numbers = 2, remains relatively stable around 0.48-0.49 up to Ablated Head Numbers = 4, and then decreases to approximately 0.46 at Ablated Head Numbers = 5.
* **SparseGPT (Purple):** Remains relatively stable around 0.50-0.51 across all Ablated Head Numbers (1-5).
* **Wanda (Blue):** Starts at approximately 0.52 at Ablated Head Numbers = 1, increases to approximately 0.55 at Ablated Head Numbers = 2, then decreases to approximately 0.51 at Ablated Head Numbers = 5.
* **Vanilla Model (Light Blue, dashed):** Remains relatively stable around 0.53-0.54 across all Ablated Head Numbers (1-5).
**Right Chart - Mean Operation:**
* **Malicious Instruct-UA (Red):** Starts at approximately 0.56 at Ablated Head Numbers = 1, decreases to approximately 0.53 at Ablated Head Numbers = 2, remains relatively stable around 0.53-0.54 up to Ablated Head Numbers = 4, and then decreases to approximately 0.51 at Ablated Head Numbers = 5.
* **Malicious Instruct-SC (Orange):** Starts at approximately 0.54 at Ablated Head Numbers = 1, decreases to approximately 0.52 at Ablated Head Numbers = 2, remains relatively stable around 0.52-0.53 up to Ablated Head Numbers = 4, and then decreases to approximately 0.50 at Ablated Head Numbers = 5.
* **Jailbreakbench-UA (Light Green):** Starts at approximately 0.49 at Ablated Head Numbers = 1, increases to approximately 0.52 at Ablated Head Numbers = 2, then decreases to approximately 0.48 at Ablated Head Numbers = 5.
* **Jailbreakbench-SC (Dark Green):** Starts at approximately 0.47 at Ablated Head Numbers = 1, increases to approximately 0.49 at Ablated Head Numbers = 2, remains relatively stable around 0.48-0.49 up to Ablated Head Numbers = 4, and then decreases to approximately 0.46 at Ablated Head Numbers = 5.
* **SparseGPT (Purple):** Remains relatively stable around 0.50-0.51 across all Ablated Head Numbers (1-5).
* **Wanda (Blue):** Starts at approximately 0.53 at Ablated Head Numbers = 1, increases to approximately 0.56 at Ablated Head Numbers = 2, then decreases to approximately 0.51 at Ablated Head Numbers = 5.
* **Vanilla Model (Light Blue, dashed):** Remains relatively stable around 0.53-0.54 across all Ablated Head Numbers (1-5).
### Key Observations
* In both charts, the "Vanilla Model" and "SparseGPT" exhibit the most stable performance across all Ablated Head Numbers.
* "Malicious Instruct-UA" and "Malicious Instruct-SC" generally have higher initial scores but tend to decrease more noticeably with increasing Ablated Head Numbers.
* "Jailbreakbench-UA" and "Jailbreakbench-SC" have the lowest initial scores and show some increase with the first few ablated heads, but then decline.
* "Wanda" shows a slight increase in performance with 2 ablated heads, then a decline.
* The performance differences between the "Scaling Operation" and "Mean Operation" are subtle but present, suggesting the operation type influences the impact of head ablation.
### Interpretation
The charts demonstrate the impact of ablating heads (removing components) from different language models on their zero-shot task performance. The consistent performance of the "Vanilla Model" suggests it is robust to head ablation, potentially indicating a well-distributed representation of knowledge. The decline in performance for models like "Malicious Instruct-UA" and "Malicious Instruct-SC" with increasing ablation suggests these models rely more heavily on specific heads for their performance, making them more vulnerable to disruption. The relatively stable performance of "SparseGPT" could be attributed to its inherent sparsity, which may make it less reliant on any single head. The differences between the "Scaling Operation" and "Mean Operation" charts suggest that the method used to train or operate the model influences its sensitivity to head ablation. The data suggests that removing heads can degrade performance, particularly for models specifically trained for adversarial tasks (like jailbreaking). The charts provide insights into the model's internal workings and the importance of different components for achieving zero-shot task performance.