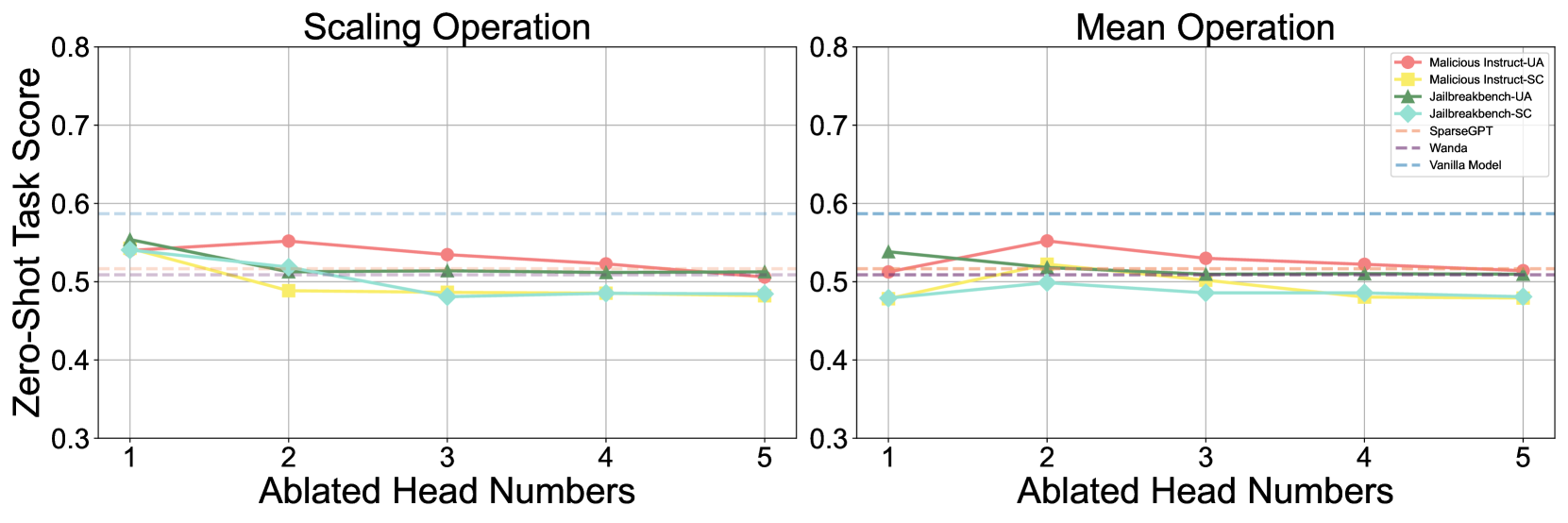
\n
## Comparative Line Chart: Scaling Operation vs. Mean Operation
### Overview
The image displays two side-by-side line charts comparing the performance of various model ablation or pruning methods under two different operations: "Scaling Operation" (left panel) and "Mean Operation" (right panel). The performance metric is the "Zero-Shot Task Score" plotted against the number of "Ablated Head Numbers." A baseline "Vanilla Model" performance is shown as a horizontal dashed line for reference.
### Components/Axes
* **Chart Type:** Two-panel comparative line chart.
* **Panel Titles:**
* Left Panel: "Scaling Operation"
* Right Panel: "Mean Operation"
* **Y-Axis (Both Panels):**
* **Label:** "Zero-Shot Task Score"
* **Scale:** Linear, ranging from 0.3 to 0.8.
* **Major Ticks:** 0.3, 0.4, 0.5, 0.6, 0.7, 0.8.
* **X-Axis (Both Panels):**
* **Label:** "Ablated Head Numbers"
* **Scale:** Discrete integers from 1 to 5.
* **Major Ticks:** 1, 2, 3, 4, 5.
* **Legend (Top-Right of Right Panel):**
* **Position:** Located in the top-right corner of the "Mean Operation" chart, overlapping the plot area.
* **Items (with corresponding visual markers):**
1. `Malicious Instruct-UA`: Red line with circular markers.
2. `Malicious Instruct-SC`: Yellow line with square markers.
3. `Jailbreakbench-UA`: Green line with upward-pointing triangle markers.
4. `Jailbreakbench-SC`: Cyan line with diamond markers.
5. `SparseGPT`: Orange dashed line.
6. `Wanda`: Purple dashed line.
7. `Vanilla Model`: Light blue dashed line.
* **Baseline Reference:** A horizontal, light blue dashed line labeled "Vanilla Model" appears at approximately y = 0.59 in both charts.
### Detailed Analysis
#### **Left Panel: Scaling Operation**
* **Vanilla Model Baseline:** Constant at ~0.59.
* **Trend Analysis & Data Points (Approximate):**
* **Malicious Instruct-UA (Red, Circle):** Starts at ~0.55 (x=1), peaks at ~0.56 (x=2), then gradually declines to ~0.51 (x=5). Overall trend: slight initial rise followed by a steady decline.
* **Malicious Instruct-SC (Yellow, Square):** Starts at ~0.54 (x=1), drops to ~0.49 (x=2), and remains relatively flat around 0.48-0.49 for x=3,4,5. Overall trend: sharp initial drop, then plateau.
* **Jailbreakbench-UA (Green, Triangle):** Starts highest at ~0.56 (x=1), declines steadily to ~0.51 (x=5). Overall trend: consistent downward slope.
* **Jailbreakbench-SC (Cyan, Diamond):** Starts at ~0.54 (x=1), drops to ~0.51 (x=2), then to ~0.48 (x=3), and remains flat at ~0.48 for x=4,5. Overall trend: decline followed by plateau.
* **SparseGPT (Orange, Dashed):** Appears as a nearly flat line just above 0.51 across all x values.
* **Wanda (Purple, Dashed):** Appears as a nearly flat line at approximately 0.51 across all x values.
#### **Right Panel: Mean Operation**
* **Vanilla Model Baseline:** Constant at ~0.59.
* **Trend Analysis & Data Points (Approximate):**
* **Malicious Instruct-UA (Red, Circle):** Starts at ~0.51 (x=1), peaks at ~0.56 (x=2), then declines to ~0.51 (x=5). Overall trend: distinct peak at x=2.
* **Malicious Instruct-SC (Yellow, Square):** Starts at ~0.48 (x=1), rises to ~0.52 (x=2), then declines to ~0.48 (x=5). Overall trend: small peak at x=2.
* **Jailbreakbench-UA (Green, Triangle):** Starts at ~0.54 (x=1), declines to ~0.51 (x=2), and remains flat around 0.51 for x=3,4,5. Overall trend: initial drop, then plateau.
* **Jailbreakbench-SC (Cyan, Diamond):** Starts at ~0.48 (x=1), rises slightly to ~0.50 (x=2), then declines to ~0.48 (x=5). Overall trend: slight initial rise, then decline.
* **SparseGPT (Orange, Dashed):** Appears as a nearly flat line just above 0.51 across all x values.
* **Wanda (Purple, Dashed):** Appears as a nearly flat line at approximately 0.51 across all x values.
### Key Observations
1. **Baseline Performance:** All tested methods, across both operations and all ablation levels, perform below the "Vanilla Model" baseline of ~0.59.
2. **Operation Impact:** The "Scaling Operation" generally results in a more consistent downward trend for most methods as more heads are ablated. The "Mean Operation" shows more varied behavior, with some methods (e.g., Malicious Instruct-UA, Malicious Instruct-SC) exhibiting a performance peak at 2 ablated heads before declining.
3. **Method Comparison:**
* `Malicious Instruct-UA` (Red) often achieves the highest score among the ablated methods, particularly at 2 ablated heads in both operations.
* `Jailbreakbench-SC` (Cyan) and `Malicious Instruct-SC` (Yellow) frequently show the lowest performance, especially at higher ablation numbers.
* `SparseGPT` and `Wanda` (dashed lines) show remarkably stable performance across all ablation levels, hovering just above 0.51, suggesting their performance is less sensitive to the number of heads ablated under these operations.
4. **Ablation Sensitivity:** Performance for most methods does not degrade linearly. There are often plateaus or even slight recoveries (peaks) before further decline, indicating a non-monotonic relationship between the number of ablated heads and task performance.
### Interpretation
This chart likely evaluates the robustness or side-effects of model compression/ablation techniques (like SparseGPT, Wanda) on a model's zero-shot capabilities, specifically when applied to "malicious instruction" or "jailbreak" benchmarks. The "Scaling" and "Mean" operations probably refer to different ways of handling parameters during the ablation process.
The key finding is that **ablating attention heads negatively impacts zero-shot performance on these sensitive tasks compared to the original (Vanilla) model.** The "Mean Operation" appears to create a more complex, non-linear response, where removing a small number of heads (2) can sometimes be less detrimental than removing just one. The stability of SparseGPT and Wanda suggests these methods preserve this specific zero-shot capability more consistently across different ablation levels, albeit at a reduced performance level. The data implies a trade-off: model compression via head ablation comes at a measurable cost to performance on these specific, potentially safety-critical, benchmarks.