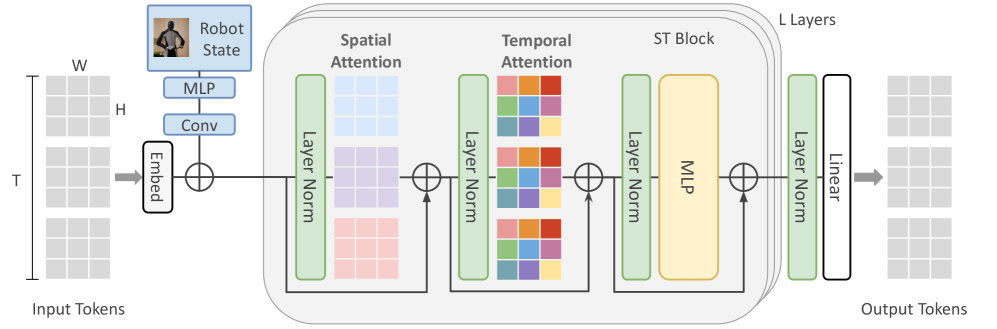
## Diagram: Spatio-Temporal Attention Block
### Overview
The image is a diagram illustrating the architecture of a Spatio-Temporal (ST) attention block within a larger neural network. The diagram shows the flow of data from input tokens, through embedding, spatial and temporal attention mechanisms, and finally to output tokens. The diagram includes components such as Layer Normalization, Multi-Layer Perceptrons (MLPs), and linear transformations.
### Components/Axes
* **Input Tokens:** Represented as a stack of three grids, labeled with dimensions T, H, and W.
* **Embed:** A block that embeds the input tokens.
* **Robot State:** A block containing an image of a robot, followed by MLP and Conv layers.
* **Spatial Attention:** A block that performs spatial attention, including Layer Norm.
* **Temporal Attention:** A block that performs temporal attention, including Layer Norm.
* **ST Block:** A block containing both Spatial and Temporal Attention, and an MLP.
* **L Layers:** Indicates that the ST Block is repeated L times.
* **Layer Norm:** A normalization layer.
* **MLP:** Multi-Layer Perceptron.
* **Linear:** A linear transformation layer.
* **Output Tokens:** Represented as a stack of three grids, similar to the input tokens.
### Detailed Analysis
1. **Input Tokens:** The input consists of a stack of three grids, labeled with T, H, and W, representing the temporal, height, and width dimensions, respectively.
2. **Embedding:** The input tokens are passed through an "Embed" block, which transforms them into a suitable representation for further processing.
3. **Robot State:** The robot state is processed through MLP and Conv layers. The output of the embedding and the robot state are added together.
4. **Spatial Attention:** The embedded tokens are then fed into a Spatial Attention block. This block includes a Layer Norm, followed by an attention mechanism represented by a grid, and another Layer Norm.
5. **Temporal Attention:** The output of the Spatial Attention block is fed into a Temporal Attention block. This block includes a Layer Norm, followed by an attention mechanism represented by a grid with colored squares, and another Layer Norm.
6. **ST Block:** The Spatial and Temporal Attention blocks are combined into an ST Block, which also includes an MLP.
7. **L Layers:** The ST Block is repeated L times, indicating that the network consists of multiple layers of these blocks.
8. **Output Tokens:** Finally, the output of the L layers is passed through a Layer Norm and a Linear transformation layer to produce the output tokens.
### Key Observations
* The diagram highlights the flow of data through the Spatio-Temporal attention mechanism.
* The use of Layer Norm is consistent throughout the architecture.
* The ST Block is the core component of the network, repeated L times.
### Interpretation
The diagram illustrates a neural network architecture designed to process spatio-temporal data, likely for tasks involving robot perception or action. The network uses attention mechanisms to focus on relevant spatial and temporal features in the input. The repetition of the ST Block allows the network to learn hierarchical representations of the data. The inclusion of a "Robot State" input suggests that the network is designed to incorporate information about the robot's current state into its processing. The diagram provides a high-level overview of the network architecture and its key components.