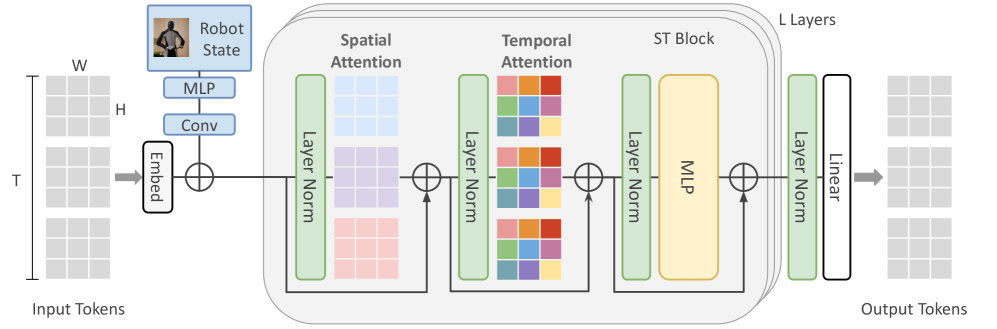
## Diagram: Spatio-Temporal Block Architecture
### Overview
The image depicts a diagram of a spatio-temporal block architecture, likely used in a neural network for processing sequential data, potentially related to robot state estimation. The diagram illustrates the flow of data through several layers, including embedding, convolutional layers, attention mechanisms (spatial and temporal), and multi-layer perceptrons (MLPs). The architecture appears to be repeated 'L' times, as indicated by the "L Layers" label.
### Components/Axes
The diagram consists of the following components:
* **Input Tokens:** Represented by a 3D grid with dimensions W (Width), H (Height), and T (Time).
* **Robot State:** A visual representation of a robot, indicating this data is likely related to robot control or perception.
* **MLP:** Multi-Layer Perceptron blocks.
* **Conv:** Convolutional layer.
* **Embed:** Embedding layer.
* **Layer Norm:** Layer Normalization blocks.
* **Spatial Attention:** A block focusing on spatial relationships within the data.
* **Temporal Attention:** A block focusing on temporal relationships within the data.
* **ST Block:** A combined Spatio-Temporal block.
* **Linear:** A linear transformation layer.
* **Output Tokens:** The final output of the architecture.
* **L Layers:** Indicates the repetition of the ST Block 'L' times.
### Detailed Analysis or Content Details
The data flow proceeds as follows:
1. **Input Tokens:** The input data is a 3D tensor with dimensions W, H, and T.
2. **Embedding:** The input tokens are passed through an embedding layer ("Embed").
3. **Convolution:** The embedded data is then processed by a convolutional layer ("Conv").
4. **Addition:** The output of the convolutional layer is added to the embedded data (represented by the circle with a plus sign).
5. **Layer Normalization (1st):** The result is then passed through a Layer Normalization block ("Layer Norm").
6. **Spatial Attention:** The normalized data is fed into a Spatial Attention block. The block contains a grid of colored squares, suggesting attention weights are learned across spatial dimensions. The colors are: light blue, purple, orange, red, and green.
7. **Addition:** The output of the Spatial Attention block is added to the output of the previous Layer Normalization block.
8. **Layer Normalization (2nd):** The result is then passed through another Layer Normalization block ("Layer Norm").
9. **Temporal Attention:** The normalized data is fed into a Temporal Attention block. This block also contains a grid of colored squares, suggesting attention weights are learned across temporal dimensions. The colors are: light blue, purple, orange, red, and green.
10. **Addition:** The output of the Temporal Attention block is added to the output of the previous Layer Normalization block.
11. **Layer Normalization (3rd):** The result is then passed through another Layer Normalization block ("Layer Norm").
12. **ST Block:** The normalized data is fed into an ST Block, which contains an MLP.
13. **Layer Normalization (4th):** The output of the ST Block is passed through another Layer Normalization block ("Layer Norm").
14. **Linear:** The normalized data is fed into a Linear layer.
15. **Output Tokens:** The final output of the architecture.
16. **Repetition:** The entire process from Spatial Attention to Linear is repeated 'L' times.
The dimensions W, H, and T are labeled on the left side of the diagram, indicating the input tensor's shape.
### Key Observations
* The architecture heavily relies on attention mechanisms (Spatial and Temporal) to process the input data.
* Layer Normalization is used extensively throughout the architecture, likely to improve training stability and performance.
* The use of MLPs within the ST Block suggests non-linear transformations are applied to the spatio-temporal features.
* The diagram does not provide specific numerical values for the dimensions W, H, T, or L.
* The color scheme within the attention blocks appears to be consistent, potentially representing different attention weights or feature maps.
### Interpretation
This diagram illustrates a neural network architecture designed to process sequential data with both spatial and temporal dependencies. The use of attention mechanisms allows the network to focus on the most relevant parts of the input data, while the repeated ST blocks enable the network to learn complex spatio-temporal representations. The "Robot State" label suggests this architecture is intended for applications involving robot perception or control, where understanding the robot's environment and its own state over time is crucial. The architecture is likely used for tasks such as predicting future robot states, planning robot actions, or recognizing objects in the robot's environment. The lack of specific numerical values suggests this is a high-level architectural overview rather than a detailed implementation specification. The consistent color scheme in the attention blocks suggests a systematic approach to feature extraction and weighting.