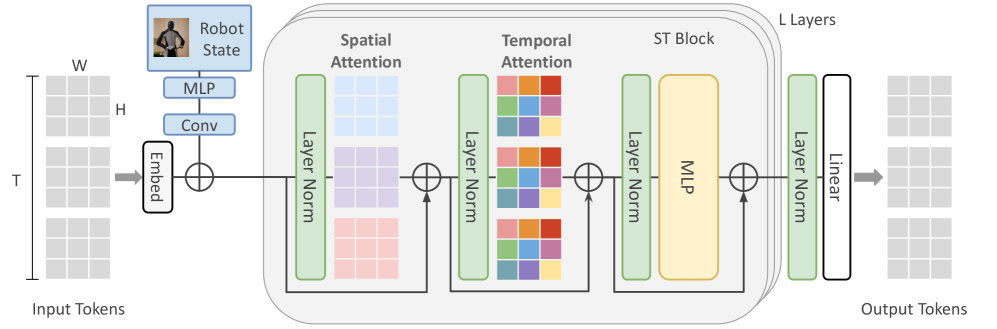
## Neural Network Architecture Diagram: Robot State Processing System
### Overview
The diagram illustrates a multi-layered neural network architecture designed for processing robot state data. It features sequential processing of input tokens through embedding, spatial and temporal attention mechanisms, an ST block with an MLP, and linear output layers. The system emphasizes spatial-temporal feature integration for robotics applications.
### Components/Axes
1. **Input Section**:
- **Input Tokens**: 3D tensor structure (W x H x T) representing spatial-temporal data
- **Embed Layer**: Converts input tokens into dense vector representations
2. **Processing Layers**:
- **Spatial Attention**: Processes W x H dimensions with attention weights
- **Temporal Attention**: Processes T dimension with attention weights
- **Layer Norm**: Normalization applied after each attention mechanism
- **ST Block**: Contains MLP for spatial-temporal feature integration
- **Linear Layer**: Final transformation to output tokens
3. **Output Section**:
- **Output Tokens**: Processed data after L layers of transformation
### Detailed Analysis
- **Input Dimensions**:
- Width (W) and Height (H) represent spatial dimensions
- Time steps (T) represent temporal dimension
- Input tokens structured as W x H x T 3D tensor
- **Attention Mechanisms**:
- Spatial Attention: 3x3 grid visualization with attention weights
- Temporal Attention: 3x3 grid visualization with attention weights
- Both attention mechanisms use color-coded weights (blue, purple, pink for spatial; red, orange, green, yellow for temporal)
- **Layer Normalization**:
- Applied after each attention mechanism
- Green rectangles indicate normalization operations
- **ST Block**:
- Contains MLP (orange rectangle) for feature integration
- Followed by layer normalization
- **Output Transformation**:
- Linear layer (white rectangle) maps processed features to output tokens
### Key Observations
1. **Spatial-Temporal Integration**:
- Separate attention mechanisms for spatial (W x H) and temporal (T) dimensions
- Combined processing in ST block suggests hierarchical feature extraction
2. **Normalization Strategy**:
- Layer normalization after each attention mechanism indicates focus on stable training dynamics
3. **Architecture Depth**:
- "L Layers" notation suggests configurable depth for the network
4. **Output Structure**:
- Final linear layer implies direct mapping to desired output space
### Interpretation
This architecture demonstrates a sophisticated approach to robot state processing by:
1. **Multi-modal Attention**: Separating spatial and temporal attention allows specialized processing of different data dimensions
2. **Feature Integration**: The ST block's MLP combines attended features for higher-level representation
3. **Normalization**: Layer normalization after each attention mechanism helps manage gradient flow in deep networks
4. **Scalability**: The "L Layers" notation suggests the architecture can be deepened for complex tasks
The design appears optimized for robotics applications requiring understanding of both spatial relationships (e.g., object positions) and temporal dynamics (e.g., movement sequences). The attention mechanisms enable the model to focus on relevant spatial regions and time steps, while the ST block facilitates cross-modal feature integration crucial for tasks like navigation or action prediction.