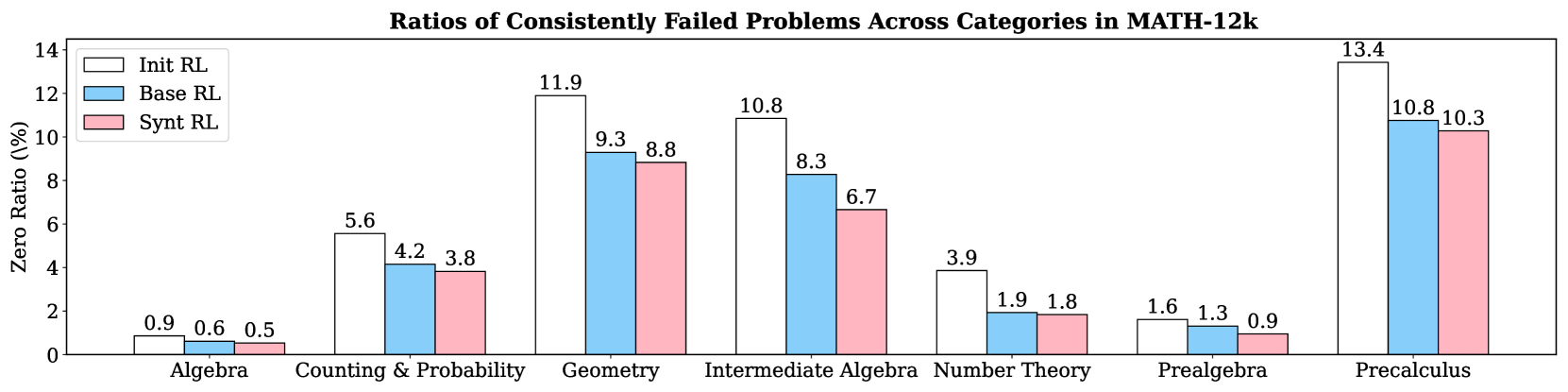
## Bar Chart: Ratios of Consistently Failed Problems Across Categories in MATH-12k
### Overview
The chart compares failure rates (Zero Ratio %) of three reinforcement learning (RL) methods—Init RL, Base RL, and Synt RL—across seven math categories in the MATH-12k dataset. Bars are color-coded (white = Init RL, blue = Base RL, pink = Synt RL) and labeled with exact values.
### Components/Axes
- **X-axis**: Math categories (Algebra, Counting & Probability, Geometry, Intermediate Algebra, Number Theory, Prealgebra, Precalculus).
- **Y-axis**: Zero Ratio (%) from 0 to 14.
- **Legend**: Top-left corner, mapping colors to RL methods.
- **Bars**: Grouped by category, with three bars per category (one per RL method).
### Detailed Analysis
1. **Algebra**:
- Init RL: 0.9%
- Base RL: 0.6%
- Synt RL: 0.5%
2. **Counting & Probability**:
- Init RL: 5.6%
- Base RL: 4.2%
- Synt RL: 3.8%
3. **Geometry**:
- Init RL: 11.9%
- Base RL: 9.3%
- Synt RL: 8.8%
4. **Intermediate Algebra**:
- Init RL: 10.8%
- Base RL: 8.3%
- Synt RL: 6.7%
5. **Number Theory**:
- Init RL: 3.9%
- Base RL: 1.9%
- Synt RL: 1.8%
6. **Prealgebra**:
- Init RL: 1.6%
- Base RL: 1.3%
- Synt RL: 0.9%
7. **Precalculus**:
- Init RL: 13.4%
- Base RL: 10.8%
- Synt RL: 10.3%
### Key Observations
- **Highest Failure Rates**:
- Precalculus dominates for all methods (13.4% Init RL, 10.8% Base RL, 10.3% Synt RL).
- Geometry also shows high failure rates (11.9% Init RL, 9.3% Base RL, 8.8% Synt RL).
- **Lowest Failure Rates**:
- Algebra has minimal failures (0.9% Init RL, 0.6% Base RL, 0.5% Synt RL).
- **Trends**:
- **Init RL** consistently has the highest failure ratios across all categories.
- **Synt RL** generally outperforms Base RL, with the largest gap in Intermediate Algebra (6.7% vs. 8.3%).
- Precalculus is an outlier, with all methods failing at rates >10%.
### Interpretation
The data suggests that **Synt RL** is the most robust method, reducing failure rates by ~20-30% compared to Init RL in most categories. However, **Precalculus remains a systemic challenge**, indicating either inherent complexity or insufficient training data for this category. The consistent underperformance of Init RL implies it may lack critical optimizations present in Base RL and Synt RL. Geometry and Precalculus warrant further investigation to address their high failure rates.