## Radar Chart: Model Performance Comparison
### Overview
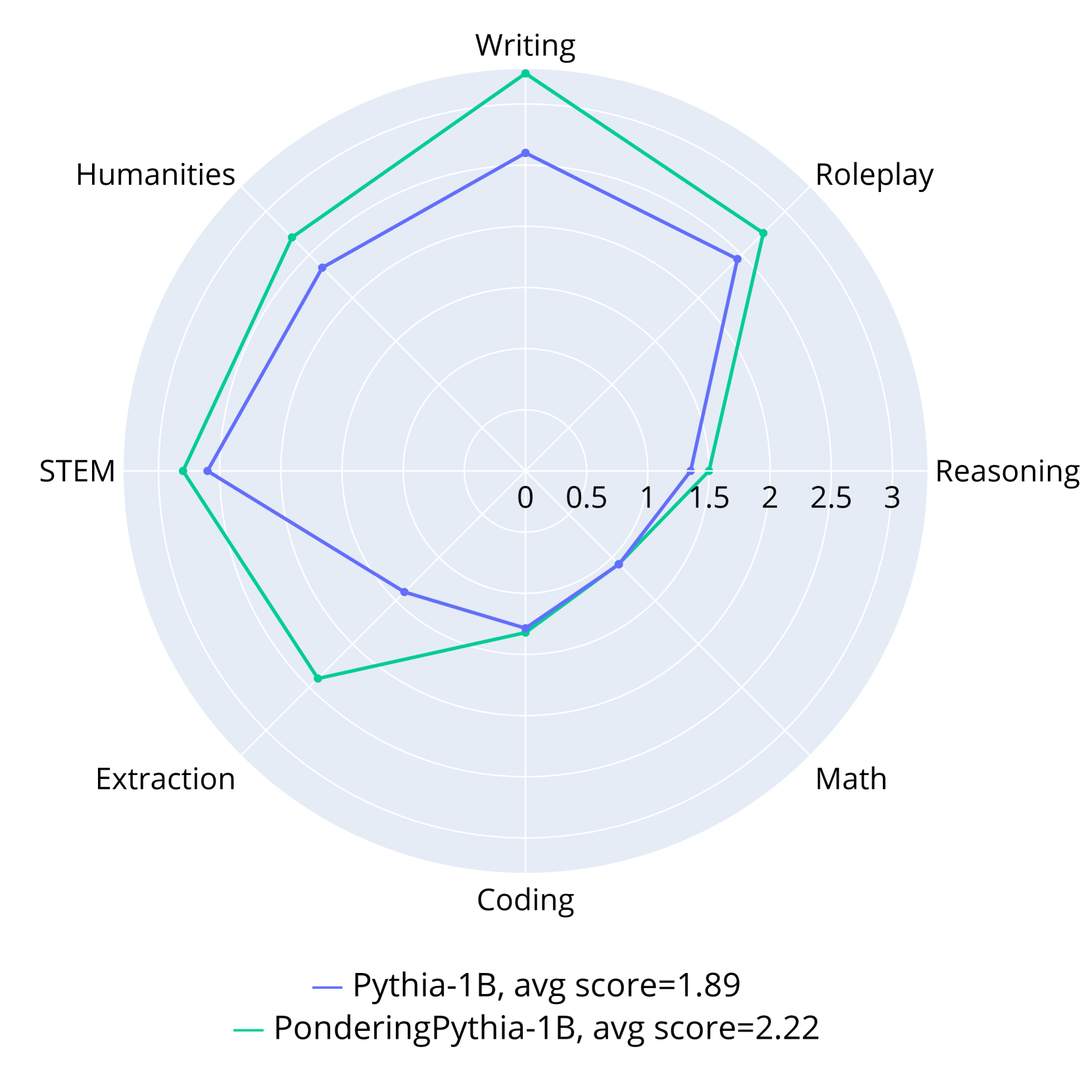
The image is a radar chart comparing the performance of two models, "Pythia-1B" and "PonderingPythia-1B," across several categories: Writing, Roleplay, Reasoning, Math, Coding, Extraction, STEM, and Humanities. The chart visualizes the strengths and weaknesses of each model in these categories, with scores ranging from 0 to 3.
### Components/Axes
* **Categories (Axes):** Writing, Roleplay, Reasoning, Math, Coding, Extraction, STEM, Humanities. These are arranged radially around the chart.
* **Scale:** The radial scale ranges from 0 to 3, with increments of 0.5.
* **Data Series:**
* Pythia-1B (blue line, avg score=1.89)
* PonderingPythia-1B (green line, avg score=2.22)
* **Legend:** Located at the bottom of the chart, it identifies the models and their corresponding colors.
### Detailed Analysis
Here's a breakdown of the performance of each model in each category:
* **Writing:**
* Pythia-1B: Approximately 1.9
* PonderingPythia-1B: Approximately 2.7
* **Roleplay:**
* Pythia-1B: Approximately 1.8
* PonderingPythia-1B: Approximately 2.1
* **Reasoning:**
* Pythia-1B: Approximately 1.5
* PonderingPythia-1B: Approximately 1.6
* **Math:**
* Pythia-1B: Approximately 1.2
* PonderingPythia-1B: Approximately 1.4
* **Coding:**
* Pythia-1B: Approximately 0.8
* PonderingPythia-1B: Approximately 1.1
* **Extraction:**
* Pythia-1B: Approximately 0.7
* PonderingPythia-1B: Approximately 1.6
* **STEM:**
* Pythia-1B: Approximately 1.0
* PonderingPythia-1B: Approximately 2.0
* **Humanities:**
* Pythia-1B: Approximately 1.5
* PonderingPythia-1B: Approximately 2.3
### Key Observations
* PonderingPythia-1B consistently outperforms Pythia-1B across all categories.
* Both models show relatively high performance in Writing and Roleplay.
* Both models show relatively low performance in Coding and Extraction.
* The largest performance difference between the two models is in STEM and Extraction.
### Interpretation
The radar chart provides a clear visual comparison of the two models' capabilities. PonderingPythia-1B demonstrates a higher average score (2.22) compared to Pythia-1B (1.89), indicating an overall better performance. The chart highlights specific areas where PonderingPythia-1B excels, particularly in STEM and Extraction, suggesting that modifications made in "PonderingPythia-1B" have significantly improved its performance in these areas. The relatively lower scores in Coding and Extraction for both models suggest these are areas that could benefit from further development and refinement. The data suggests that "PonderingPythia-1B" is a more well-rounded model with improvements across the board, but both models have areas for potential improvement.