## Radar Chart: Model Performance Comparison
### Overview
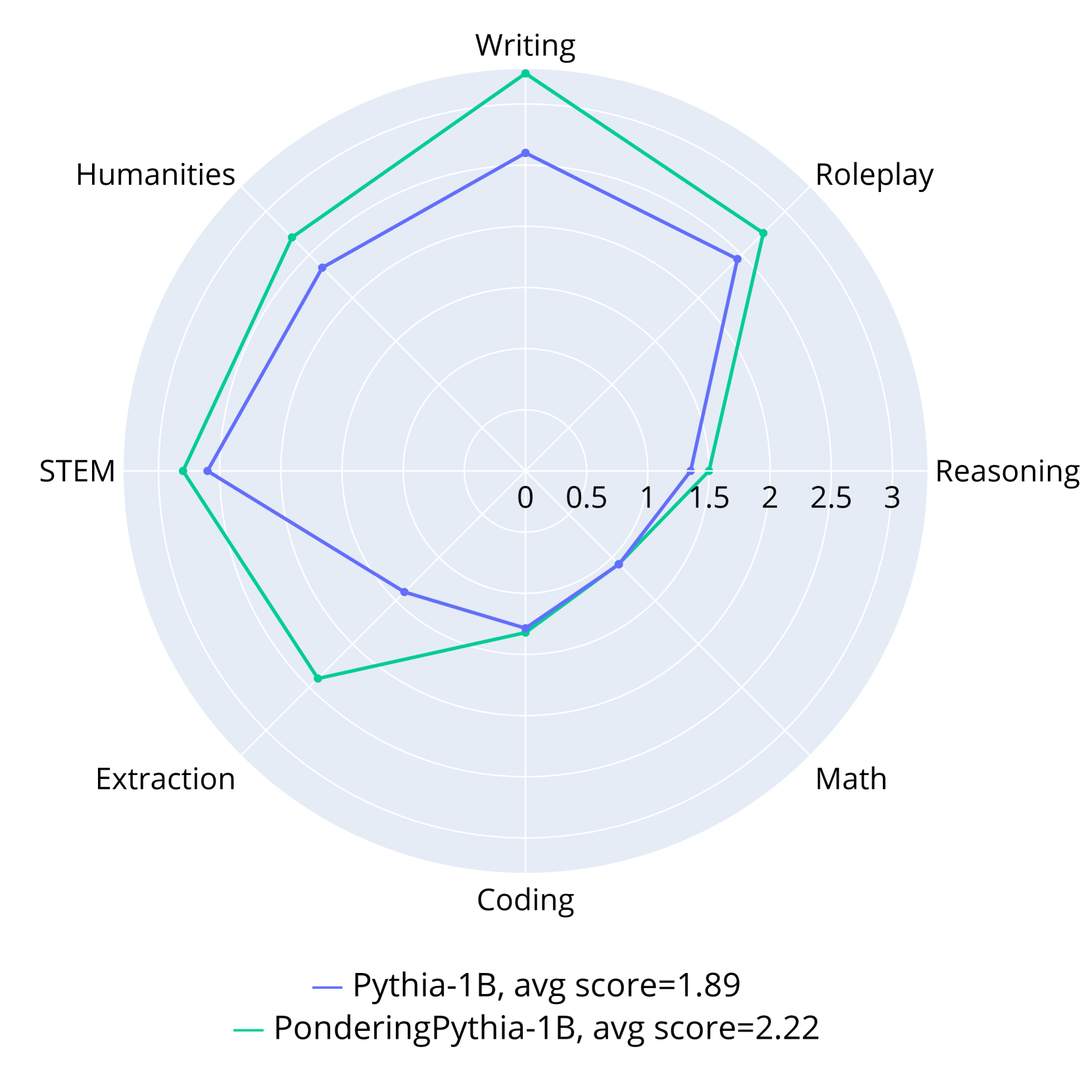
This image is a radar chart (spider plot) comparing the performance of two AI language models across eight distinct capability categories. The chart visually represents the relative strengths and weaknesses of each model on a common scale.
### Components/Axes
* **Chart Type:** Radar Chart.
* **Categories (Axes):** Eight axes radiate from the center, each representing a skill domain. Clockwise from the top:
1. Writing
2. Roleplay
3. Reasoning
4. Math
5. Coding
6. Extraction
7. STEM
8. Humanities
* **Scale:** A radial scale from the center (0) to the outer edge (3), with concentric circles marking intervals of 0.5 (0, 0.5, 1, 1.5, 2, 2.5, 3).
* **Legend:** Located at the bottom center of the chart.
* **Blue Line:** Labeled "Pythia-1B, avg score=1.89"
* **Green Line:** Labeled "PonderingPythia-1B, avg score=2.22"
### Detailed Analysis
The performance of each model is plotted as a polygon connecting its score on each axis. Values are approximate visual estimates.
**1. Pythia-1B (Blue Line, Avg Score: 1.89)**
* **Trend:** The blue polygon forms a relatively balanced, slightly irregular octagon, indicating moderate performance across most categories with no extreme peaks or valleys.
* **Approximate Scores per Category:**
* Writing: ~2.0
* Roleplay: ~1.8
* Reasoning: ~1.5
* Math: ~1.3
* Coding: ~1.4
* Extraction: ~1.6
* STEM: ~2.0
* Humanities: ~1.9
**2. PonderingPythia-1B (Green Line, Avg Score: 2.22)**
* **Trend:** The green polygon is more expansive and irregular, showing significantly higher performance in several categories, particularly on the left and top sides of the chart.
* **Approximate Scores per Category:**
* Writing: ~2.8 (Highest point on the chart)
* Roleplay: ~2.3
* Reasoning: ~1.6
* Math: ~1.4
* Coding: ~1.5
* Extraction: ~2.4
* STEM: ~2.7
* Humanities: ~2.4
### Key Observations
1. **Consistent Superiority:** The green line (PonderingPythia-1B) encloses the blue line (Pythia-1B) on every single axis, indicating it scores higher in all eight categories.
2. **Largest Gains:** The most substantial performance improvements for PonderingPythia-1B are in **Writing** (+0.8), **STEM** (+0.7), **Extraction** (+0.8), and **Humanities** (+0.5).
3. **Smallest Gains:** The smallest improvements are in **Reasoning** (+0.1), **Math** (+0.1), and **Coding** (+0.1). These categories represent the lowest scores for both models.
4. **Performance Profile:** Pythia-1B's strongest areas are Writing and STEM (~2.0). PonderingPythia-1B's profile is dominated by Writing (~2.8), followed by STEM and Extraction (~2.4-2.7).
5. **Overall Average:** The legend confirms the visual impression, with PonderingPythia-1B having a higher average score (2.22 vs. 1.89).
### Interpretation
This chart demonstrates the efficacy of the "Pondering" modification applied to the base Pythia-1B model. The data suggests that this modification leads to a broad and significant enhancement of capabilities across a diverse set of language model evaluation tasks.
* **Nature of Improvement:** The gains are not uniform. The modification appears particularly effective for tasks involving **generative and interpretive skills** (Writing, Roleplay, Humanities) and **structured information handling** (Extraction, STEM). This could imply the "pondering" mechanism improves coherence, depth of generation, or information synthesis.
* **Persistent Challenges:** Both models show their weakest performance in **formal reasoning and logic-based tasks** (Reasoning, Math, Coding). The minimal improvement in these areas suggests the modification does not fundamentally address the core challenges these tasks present for this model architecture or scale (1B parameters).
* **Strategic Implication:** For applications prioritizing creative writing, content extraction, or STEM explanation, PonderingPythia-1B offers a clear advantage. For tasks requiring rigorous mathematical proof or complex code generation, the advantage is marginal, and other model types or sizes might be necessary.
* **Underlying Mechanism:** The name "PonderingPythia" and the performance profile hint that the modification may involve a form of iterative refinement, extended internal processing, or a chain-of-thought-like mechanism that benefits tasks where "thinking before answering" is advantageous, but offers less help for tasks where the solution path is more deterministic or requires specialized symbolic reasoning skills not enhanced by the pondering process.